纠删码存储系统中的投机性部分写技术
本文已被USENIX'17年度技术大会录用,此处为中文简译版。阅读英文论文完整版请点击:Speculative Partial Writes in Erasure-Coded Systems
前言
多副本和纠删码(EC,Erasure Code)是存储系统中常见的两种数据可靠性方法。与多副本冗余不同,EC将m个原始数据块编码生成k个检验块,形成一个EC组,之后系统可最多容忍任意k个原始数据块或校验块损坏,都不会产生数据丢失。纠删码可将数据存储的冗余度降低50%以上,大大降低了存储成本,在许多大规模分布式存储系统中已得到实际应用。
EC给写操作带来了很大的额外开销,包括编解码计算开销和流程性开销两部分。在向量指令集SSE、AVX等的帮助下,一个现代CPU核心的EC编解码能力就可以达到几GB到十几GB每秒,远远大于存储设备的I/O吞吐率。这使得流程性开销成为EC写入性能的最重要制约因素。若一次写操作的偏移和长度没有对齐EC组,就需要部分更新涉及的EC组,因而将此类操作称为部分写。部分写带来了大部分的流程性开销。
处理部分写的最直接办法是将不被写的数据块读出来,跟新数据组合在一起,然后再整体编码并写入。目前Ceph、Sheepdog等系统都采用了这种办法。一种简单有效的改进是将被覆盖数据的原始值读出来,然后根据新旧数据的差值来进行增量编码,得到各个校验块的差值,并“加”到各个校验块上。这种方法可以显著减少系统总体I/O次数,然而它需要对涉及的数据块和所有校验块进行原地读写(即在同一位置进行先读后写),在没有缓存的情况下(常态),HDD需要花费8.3毫秒(7200RPM)的时间旋转一周才能完成写入请求,跟一次随机I/O的平均寻道时间相当。这样的流程极大地影响了写入效率,即便应用层面发出的是顺序写操作,最终得到的性能也跟随机写差不多。
在实际应用当中,只有写操作的偏移和长度都恰好跟EC组对齐才可以避免部分写,然而应用往往无法照顾到底层存储的实现细节和参数,所以部分写构成了写操作的主体,决定了EC存储系统的实际写性能。EC模式的部分写性能大大低于三副本写,这使得EC尚不适用于写操作较多的场合,如云硬盘。
目前业内已有许多工作对这一问题进行改进,其中最具代表性的工作是2014年发表在FAST技术会议上的“Parity Logging with Reserved Space: Towards Efficient Updates and Recovery in Erasure-coded Clustered Storage”,它的核心思路是通过在校验块上记变更日志的方式来减少其上不必要的读操作,同时将随机写变成顺序追加写,以改善写入性能。然而它并不能改善原始数据块上的写流程,这构成了大多数的写操作,所以系统总体写性能改善有限。
我们的改进思路仍然是在校验块上使用变更日志,但与传统方法有显著区别:(1)日志中记录的是数据本身,而不是校验数据的增量差值;(2)对于变更日志中涉及的每一个数据块,都需要额外记录1次且仅1次其变更前的数据,称为**\(d^{(0)}\)**;(3)校验块的更新由数据块发起,并且首次请求不附带\(d^{(0)}\),若校验块的响应明确表示需要\(d^{(0)}\),数据块再将\(d^{(0)}\)发送过去。通过这样的设计,系统可以实现在大多数情况下不需要读取并发送\(d^{(0)}\)到校验块,此为投机成功;在少数情况下投机失败,仍然需要读取并发送\(d^{(0)}\)给校验块,但投机失败的代价仅仅是增加一次网络交互延迟(大约0.1~0.2毫秒),相对于机械硬盘的寻道延迟(平均几毫秒)可以忽略不计,因而这几乎是一个“稳赚不赔”的优化。
投机性部分写:原理、设计与实现
考虑针对同一个数据条带\(d_i\)的一系列\(r\)次写操作\(d_i^{(1)}, d_i^{(2)}, \cdots, d_i^{(r)}\),校验块为\(p_j(j=1,2,\cdots,k)\),令 \(d_i^{(0)}\) 和 \(p_j^{(0)}\) 分别表示 \(d_i\) 和 \(p_j\) 的原始值。根据增量编码公式
我们有 \( \Delta p_j^{(1)}=a_{ij} \times \Delta d_i^{(1)}, \Delta p_j^{(2)}=a_{ij} \times \Delta d_i^{(2)}, \cdots, \Delta p_j^{(r)}=a_{ij} \times \Delta d_i^{(r)} \),因而可以得到
根据这一公式,最终的校验数据 \(p_j^{(r)} (j=1,2,\cdots,k)\) 只取决于\(p_j^{(0)}\), \(d_i^{(0)}\) 和 \(d_i^{(r)}\)。这一结论允许我们不必每次计算校验差值,而使用数据的最终值和原始值(即 \(d^{(r)}\) 和 \(d^{(0)}\),省略下标)之间的差值来等价计算整个过程的校验值增量。因而 \(d^{(0)}\) 只需要读取一次(在写入 \(d^{(1)}\) 的时候)。对于这一系列的\(r\)次写操作,投机只会在第一次失败,在之后的\(r-1\)次均成功,直到日志被合并进入校验数据块或遇到全量写操作。对于失败的投机,校验块会返回一个特定的错误码,以通知数据块将\(d_0\)发送过来,这仅仅带来一次网络RTT的额外开销,大约0.1ms~0.2ms,相对于磁盘I/O时间来说可以忽略。
现实当中的I/O负载也存在大块顺序的操作,这将产生整个EC组的全量写操作。对于这种操作,我们将直接计算出校验数据,并将其写入校验块,同时在变更日志中记录一个特殊操作I,表示将I之前的变更记录取消掉,因为最新的数据已经直接写到校验块内了。
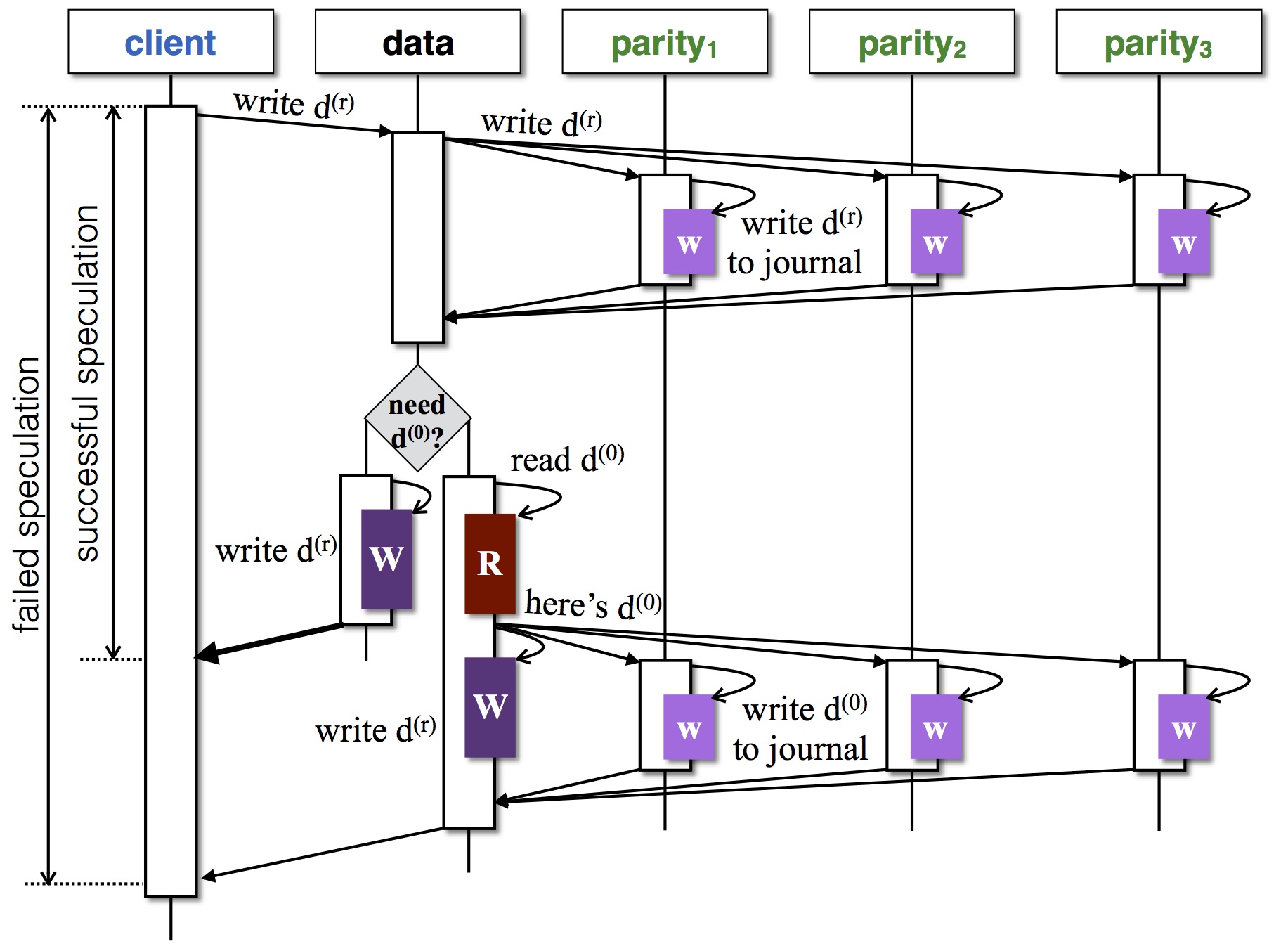
根据上述原理,我们设计出如下图所示的部分写流程(以三个校验块为例):
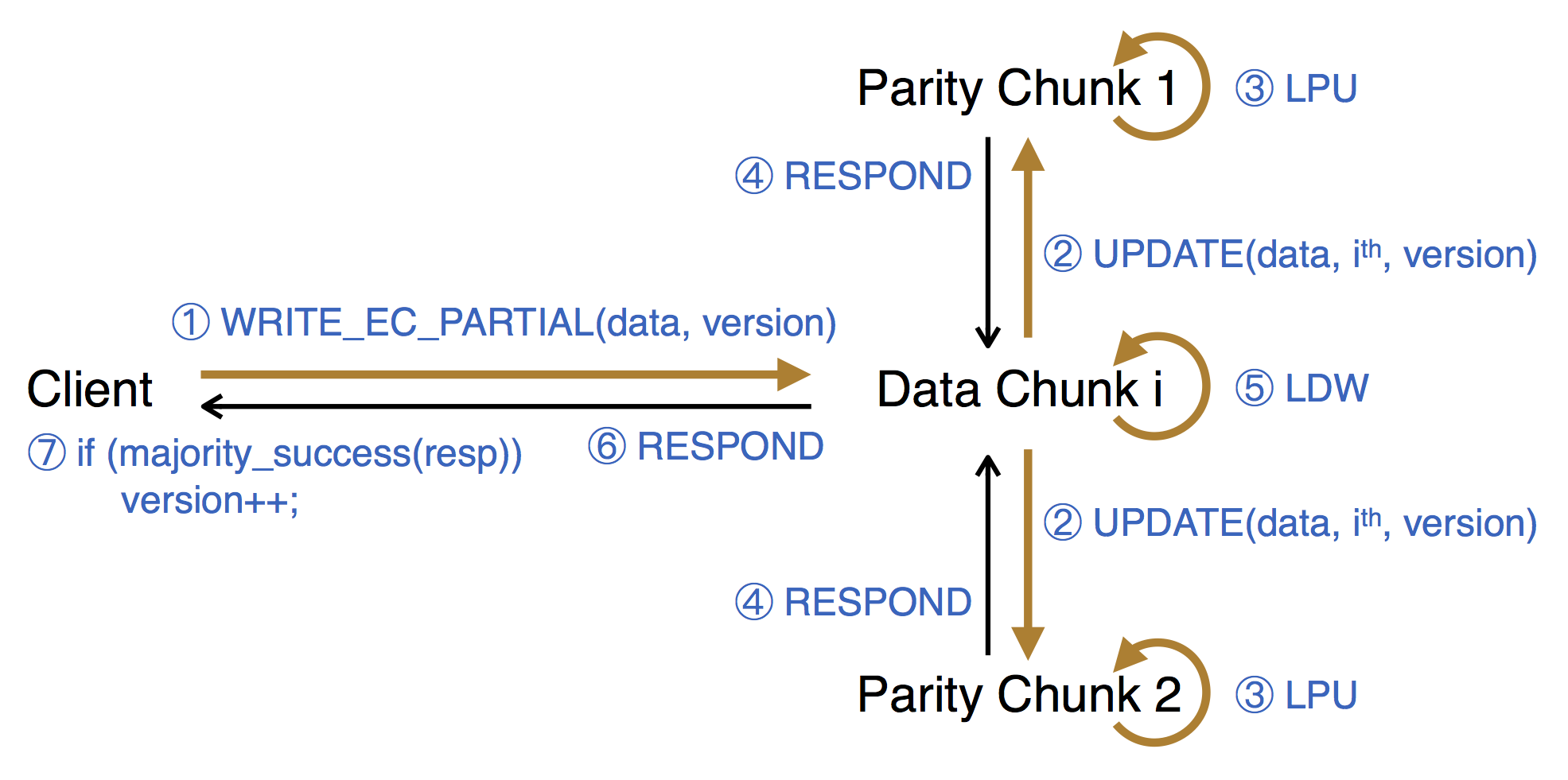
我们基于美团云现有的分布式块存储系统(参见之前的博客文章“分布式块存储系统Ursa的设计与实现”)将这一设计实现出来,称为PBS,提供强一致性保障。系统的写操作流程整体如下图所示(以两个校验块为例):
实验
EC编解码性能
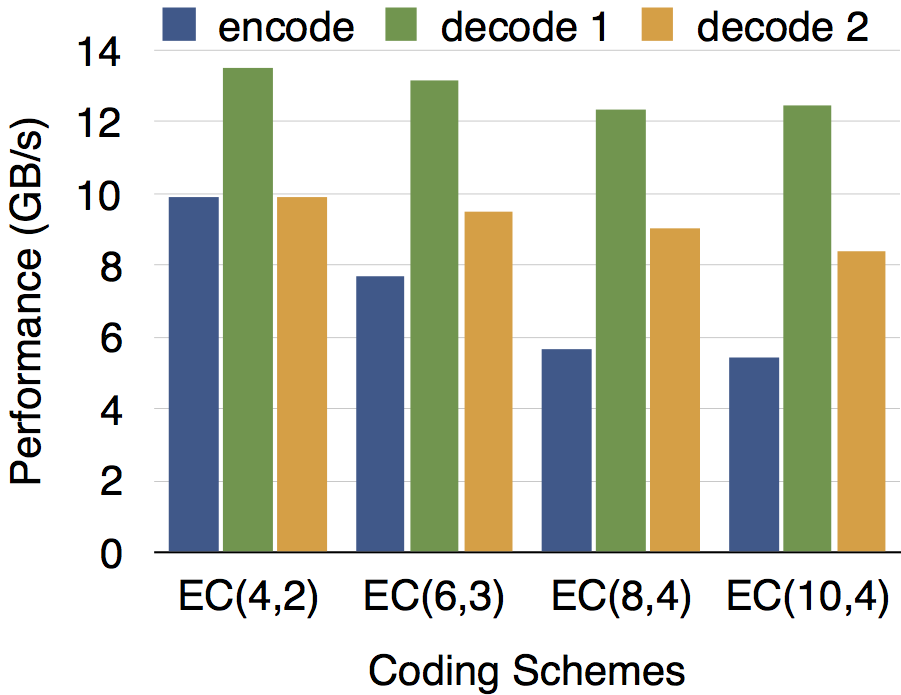
我们针对EC(4,2)、EC(6,3)、EC(8,4)、EC(10,4)等多种配置测试了编解码运算性能。如下图所示,在SSE、AVX等向量运算指令集的帮助下,现代CPU的1个核心每秒就能完成5~13GB数据量的编解码工作,远远大于同时期各种外部存储设备的吞吐率,所以编解码运算已不再成为EC存储系统的瓶颈。测试中所用CPU型号为Xeon E5-2650v3 @ 2.3GHz,图中encode表示编码,decode 1和2分别表示解码1个和2个数据块。测试表明编解码运算已经不是EC性能的瓶颈了。
PBS部分写的性能
所有的测试均在虚拟机内挂载PBS完成。我们的测试环境为10台服务器,每台配备10块硬盘,7200RPM,LSI 3008 SAS卡(无缓存)。测试了随机写IOPS,以及随机写的延迟,来衡量部分写的性能,其中I/O大小为4KB,EC组的条带大小为16KB。测试结果分别如下图所示,其中HDD表示单块7200RPM的物理硬盘的基准性能,R3表示三副本模式,PBS-1和PBS-2分别表示PBS在投机失败(首次写)和投机成功(第二次及以后)的情况,EC表示增量编码方法,PLog表示前文所述的在FAST'14技术大会发表的工作,代表了已有方法中的最好结果。
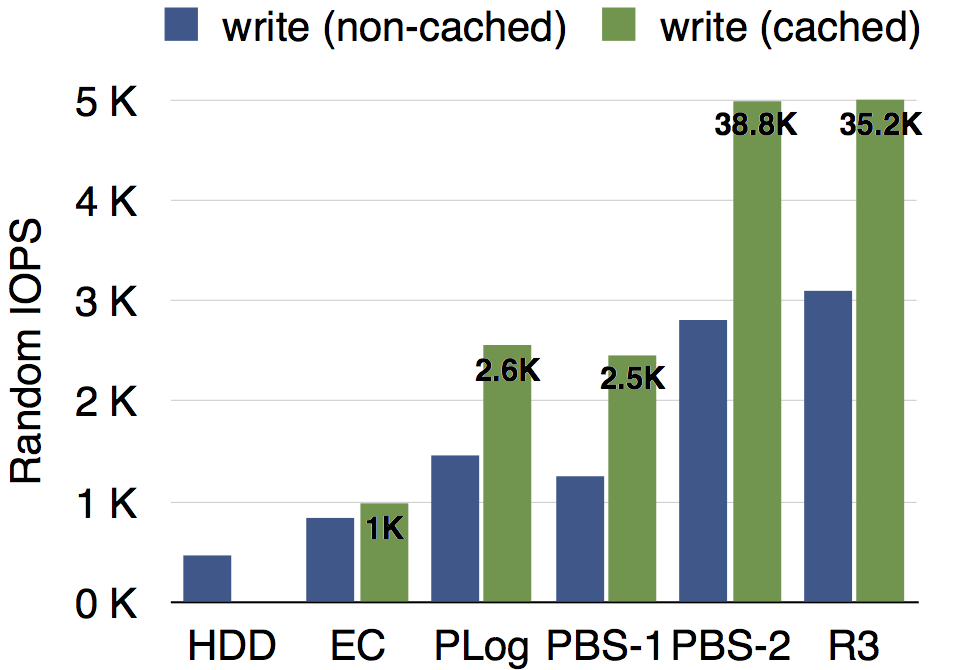
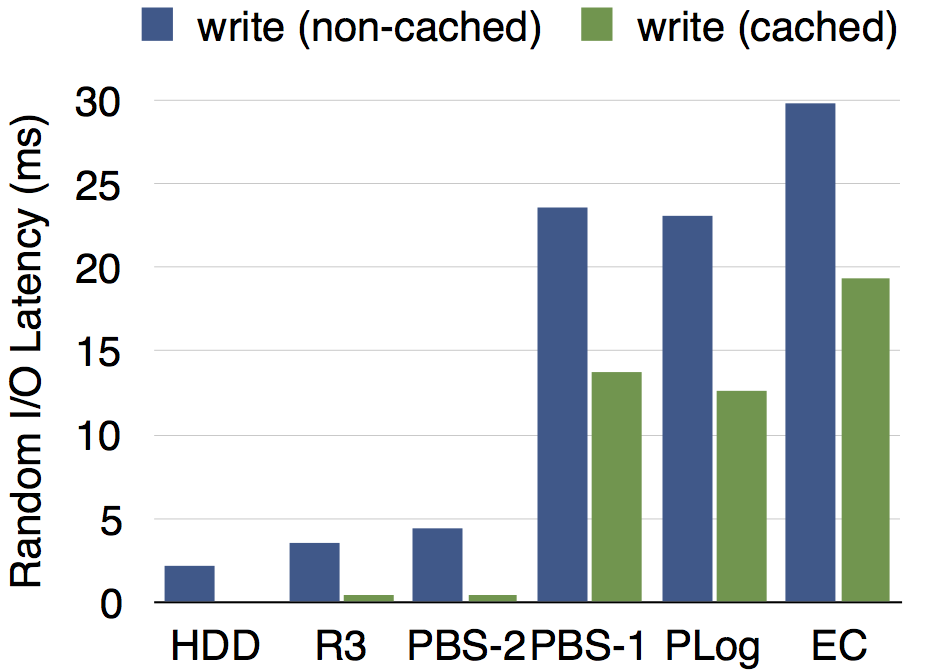
从结果可以看出,各种情况下的读性能大致相当,PBS-1(投机失败,小概率)比PLog略低,PBS-2(投机成功,大概率)远远好于PLog,甚至可以与三副本模式的性能相媲美。
故障恢复
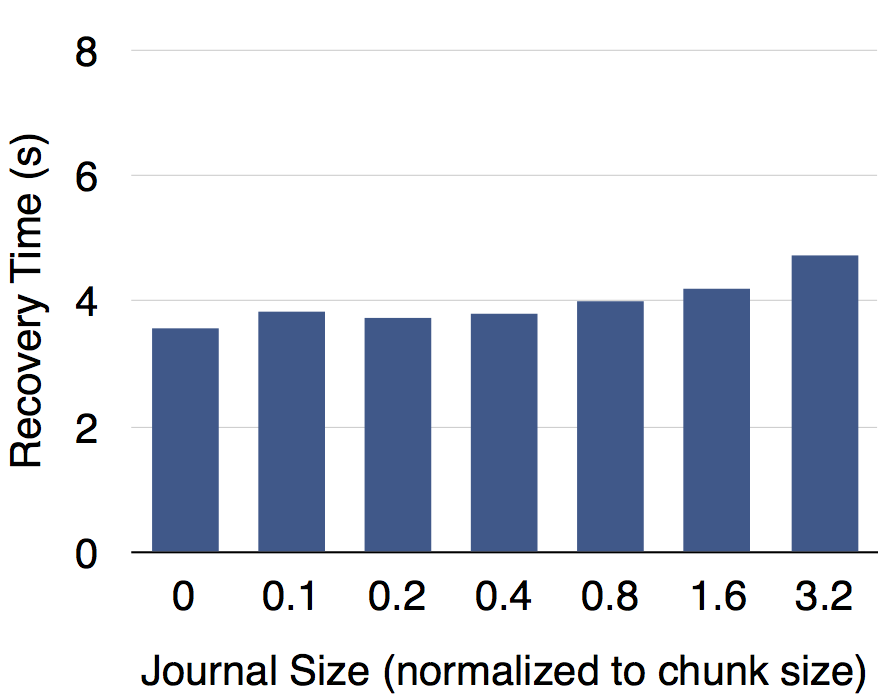
我们在内存中为日志建立了索引,因而在(故障恢复中)读取日志时可以快速定位数据偏移。如下图所示,测试结果表明日志大小对故障恢复速度的影响有限。