

大圣魔方——美团点评酒旅BI报表工具平台开发实践
背景
当前的互联网数据仓库系统里,数据中心往往存放了大量Cube化或者半Cube化的数据。如果需要将这些数据的内在关系体现出来,需要写大量的程序和SQL来发现数据之间的内在规律,往往会造成用户做非常多的重复性工作;而且由于没有数据校验的机制,还容易出错,无法直观查看各种数据(没有可视化的UI图表)。这时就急需一款基于Cube的报表工具快速为用户提供报表服务,可以完成多维查询、上卷、下钻等各种功能。为此,美团点评酒旅技术团队开发了大圣魔方。
难点
一款好的BI报表工具,需要考虑并能够解决如下问题:
- 统一数据源
- SQL生成
- 跨数据源数据聚合
- 自定义计算指标
- 数据权限
- 标准化UI组件,自助生成可视化报表
解决方案——大圣魔方
体系架构
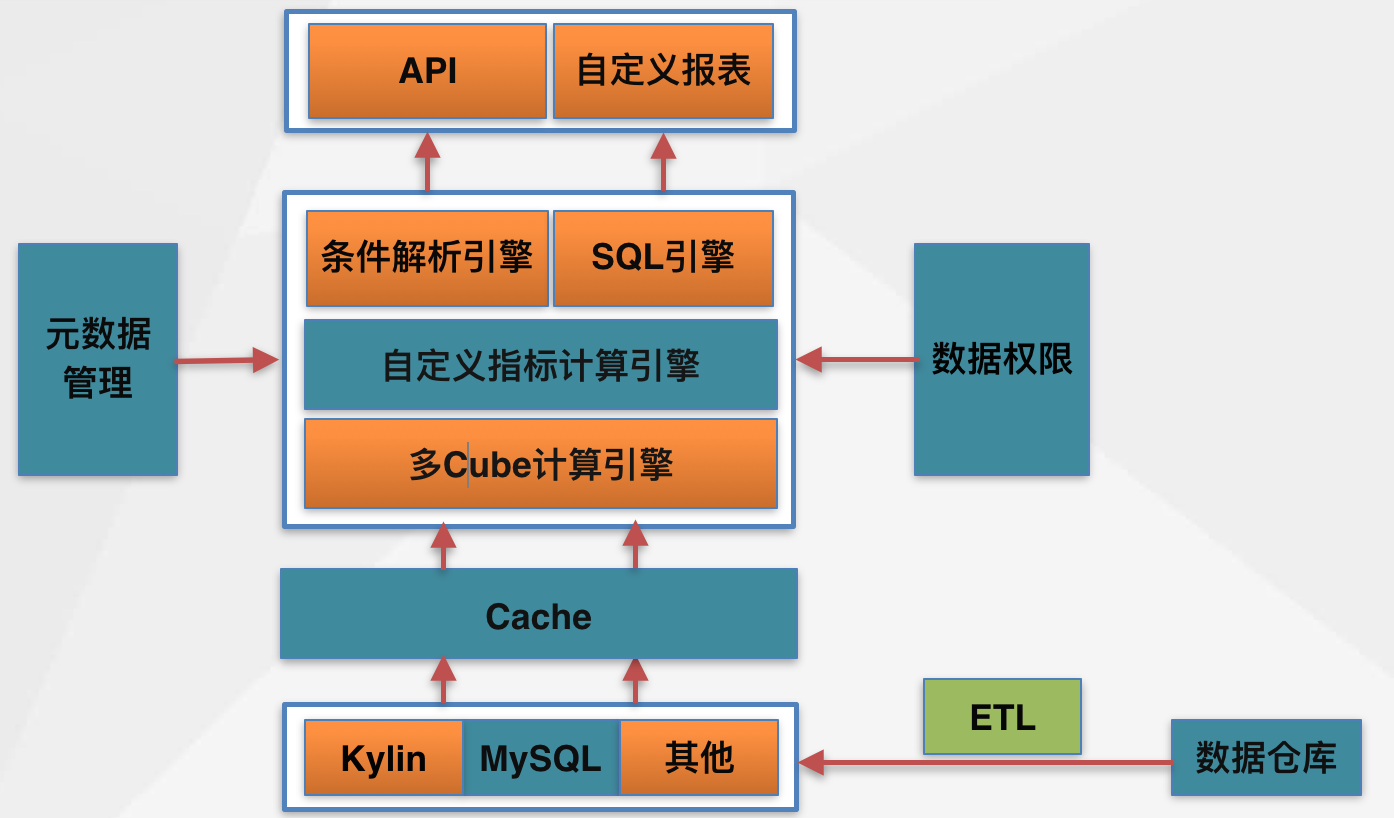
图1 大圣魔方体系架构
具体方案
1. 统一数据源
提供多数据源查询服务,需要解决的问题主要是两个:
- 以什么样的统一方式从数据源获取数据。
- 不是所有的数据源引擎都能提供OLAP服务和数据聚合的能力,我们需要从上层考虑,去实现数据的聚合、上卷、下钻、切割、自定义计算等功能。
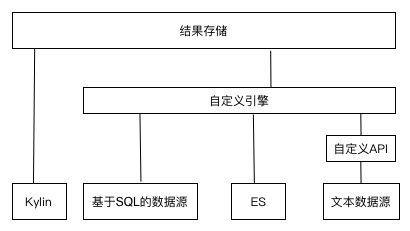
图2 大圣魔方多数据源
大圣魔方上对能够通过SQL查询的数据源,例如MySQL和Kylin都通过统一SQL查询来获取数据;对于ES(Elasticsearch)采用ES提供的API来查询;对于普通文本格式的数据采用自定义API从数据源获取数据。
如图2所示,大圣魔方只是从数据源里面获取基础的数据,之后通过实现自己的计算引擎对数据进行聚合、切割等操作,对此,魔方中设置了四个引擎,用于实现不同的功能。
2. SQL生成
对于SQL的生成也存在两个问题:
- 不是所有的支持SQL的数据源,都支持标准的SQL,同时,支持标准SQL的数据源也会支持带有自身特征的SQL。
- 根据用户选择的条件、维度和指标,动态生成SQL的核心内容。
针对第一个问题,我们对SQL模板进行了定义,当选择不同的数据源时,根据数据源的Dialect选择不同的SQL模板,而这就决定了SQL的组成部分(骨架)。
为了解决第二个问题,我们在SQL模板的基础之上做了内容填充和替换操作,选择具体的维度、指标和筛选项的值,再填充到SQL模板的不同地方,最终就会生成能够被数据源执行的SQL。
在SQL生成的时候也考虑过其它的框架,如Apache Calcite Avatica、Alibaba的Druid,但是最终都放弃了,原因也是基于两个方面:
- 这些框架庞大且功能多,适用于我们场景的SQL生成的部分API使用起来过于复杂。
- 大都是基于标准的ANSI SQL-92,很难个性化地生成我们所需要的SQL。
最终,我们采用了SQL模板和字符串填充替换操作来完成。为此我们在Java的正则表达式基础之上做了一个功能很多的字符串操作类库。
3. 跨数据源数据聚合
一般情况下,同一个数据源的大部分数据源引擎都能够支持多表的join操作,但是也存在不支持的,例如老版本的Kylin就不支持多Cube的join操作,还有一个更重要的问题是数据源引擎无法解决跨数据源的数据聚合问题,必须要自己实现数据的聚合操作,一般的情况下需要自己去实现inner join、left outer join和full outer join的逻辑。
大圣魔方实现了inner join和left outer join两个逻辑,因为full outer join的需求场景不是很多,所以没有实现。下面是大圣魔方的实现代码:
inner join核心代码
private void join(List<Map<String,String>>[] contents,List<Project> sharedList,final int n,int[] rowsStatus,LinkedList<MatchRow> result){
if(this.cubeJoin==1){
throw new java.lang.IllegalArgumentException("left join call leftJoin method,not call join method");
}
if(n<contents.length){
List<Map<String,String>> list = contents[n];
for(int k=0;k<list.size();k++) {
boolean equal = true;
if(n!=0) {
Map<String, String> prev = contents[n - 1].get(rowsStatus[n - 1]);
Map<String, String> cur = list.get(k);
for (Project proj : sharedList) {
String key = proj.fieldName.toUpperCase();
if (key.matches("^\\d+$") || key.equals("*")) {
key = "_";
}
key = proj.isCompanion() ? key + proj.getFactId() : key;
String prevValue = prev.get(key);
String curValue = cur.get(key);
if (prevValue == curValue) {
continue;
}
if (prevValue == null || curValue == null || !prevValue.equals(curValue)) {
equal = false;
break;
}
}
}
if (equal) {
rowsStatus[n] = k;
if(n==contents.length-1){//last dataset match
MatchRow mr = new MatchRow();
List<MatchRow.DatasetRow> tmp = new ArrayList<>();
for(int i=0;i<rowsStatus.length;i++){
MatchRow.DatasetRow dr = new MatchRow.DatasetRow();
dr.setDatasetIndex(i);
dr.setRowIndex(rowsStatus[i]);
tmp.add(dr);
}
mr.addMatchRow(tmp);
result.add(mr);
}else{
join(contents,sharedList,n+1,rowsStatus,result);
}
}
}
}
}
上述代码就是通过回溯算法实现inner join的核心逻辑,具体解析如下:
- contents参数表示每个数据源里面的结果集。
- sharedList表示关联的字段。
- n和rowsStatus是回溯算法记录状态用的。
- result里面包含的是符合join条件的记录。
- MatchRow里面记录的是一个数据源里面的某一行与其余的数据源里面的那一行是相等的,记录的是下标号。
只有当sharedList里面的每个字段都相等的时候,两条记录才满足inner join的条件。这个算法是一个通用算法,因为是通过回溯算法实现的,所以要join的数据源理论上可以有无限个。
left outer join核心代码
private boolean leftJoin(List<Map<String,String>>[] contents,List<Project> sharedList,final int n,int[] rowsStatus,LinkedList<MatchRow> result){
boolean leftJoinMatch = false;
if(n<contents.length){
List<Map<String,String>> list = contents[n];
for(int k=0;k<list.size();k++) {
boolean equal = true;
if(n!=0) {
//in left join,compare with the first dataset.
Map<String, String> prev = contents[0].get(rowsStatus[0]);
Map<String, String> cur = list.get(k);
for (Project proj : sharedList) {
String key = proj.fieldName.toUpperCase();
if (key.matches("^\\d+$") || key.equals("*")) {
key = "_";
}
key = proj.isCompanion() ? key + proj.getFactId() : key;
String prevValue = prev.get(key);
String curValue = cur.get(key);
if (prevValue == curValue) {
continue;
}
if (prevValue == null || curValue == null || !prevValue.equals(curValue)) {
equal = false;
break;
}
}
}
if (equal) {
leftJoinMatch = true;
rowsStatus[n] = k;
if(n==contents.length-1){//last dataset match
MatchRow mr = new MatchRow();
List<MatchRow.DatasetRow> tmp = new ArrayList<>();
for(int i=0;i<rowsStatus.length;i++){
MatchRow.DatasetRow dr = new MatchRow.DatasetRow();
dr.setDatasetIndex(i);
dr.setRowIndex(rowsStatus[i]);
tmp.add(dr);
}
mr.addMatchRow(tmp);
result.add(mr);
}else{
//if next dataset is not match,use the next's next...
for(int loopFlag=n+1;loopFlag<rowsStatus.length;loopFlag++){
boolean match = leftJoin(contents,sharedList,loopFlag,rowsStatus,result);
if(match){
break;
}
rowsStatus[loopFlag]=-1;
if(loopFlag==contents.length-1){
MatchRow mr = new MatchRow();
List<MatchRow.DatasetRow> tmp = new ArrayList<>();
for(int i=0;i<rowsStatus.length;i++){
MatchRow.DatasetRow dr = new MatchRow.DatasetRow();
dr.setDatasetIndex(i);
dr.setRowIndex(rowsStatus[i]);
tmp.add(dr);
}
mr.addMatchRow(tmp);
result.add(mr);
}
}
}
}
}
}
return leftJoinMatch;
}
上面的代码是left outer join的实现逻辑,同样也是用的回溯算法,它与inner join有2个不同之处:
- left outer join的数据源匹配逻辑是当第一个数据源与第二个数据源没有匹配的时候,会继续与第三个数据源进行匹配操作,原因是数据源的顺序导致了不匹配,继续往下匹配就可以避免这个问题。
- 行与行做相等操作的时候,右边没有匹配行的时候,左边的行继续保留,这个是left outer join的逻辑决定的。
4. 自定义计算指标
使用自定义计算的原因,主要是基于下面的两个方面:
- 数据源引擎不支持数据的混合运算或有特殊逻辑的数据处理。
- 结果数据跨数据源。
对此,我们对大圣魔方做了如下操作:
- 通过Java里面的ScriptEngine进行封装来实现数据列的混合运算,不需要自己再去写编译程序解析。对于特殊的数据处理,例如同环比这样的特殊指标,需要单独定义接口,让实现类继承改特定接口,实现类是一个特殊的指标,它需要进行多次数据查询,将最终的结果通过ScriptEngine进行运算。
- 第二个问题是在上文中“跨数据源数据聚合”的基础上实现的,数据聚合后通过ScriptEngine做最后的处理。
5. 数据权限的问题
只要是有数据展示,数据权限问题就无法避免,权限主要是分为报表的可查看权限和维度、指标权限。权限遇到的最主要的问题是构成权限矩阵的数据量太大,参与者有用户和组织,权限的实体有维度和指标,这样大的数据维护起来的成本很高;其次是权限数据配置会占用很多的人力。
对此,我们做了如下操作:
- 使用UPM控制报表的可查看权限。公司推荐使用UPM来控制权限,不过UPM也具有一定的局限性,即只能够判断用户或者组织是否满足某个权限,而不能满足获取部分权限数据的需求,例如某个用户对某个权限只拥有一部分权限,那他就无法提供具体数据。但是UPM可以提供是否的权限,所以报表的可查看权限可以使用UPM来控制,这样可以节约大量的工作。
- 使用默认任何人都有权限的机制。通过使用默认有权限的这个机制可以大大减少权限数据。需要鉴权的那些维度和指标采用默认无权限的机制,这样两种方案结合,可以最大限度地减少权限数据。
- 通过走审批流机制自助申请。通过审批流机制可以让用户走自助申请,大大节约权限数据的维护人力成本。
6. 标准化UI组件,自助生成可视化报表
报表上展示数据需要有各种各样的图表,没法为用户只做一个统一的报表,这个时候需要用户能够创建自己想要的报表,这时需要提供一个标准的组件库、布局库和一些常用的模板。用户选择好想要的模板,然后选择布局对报表页面进行布局,接着在每个布局里面填充不同的组件,这样就可以构建一张报表了,也就是我们常说的所见即所得的方式。
大圣魔方就是采用上述的机制提供了一套可视化报表编辑工具。使用它可以快速地创建一个报表,管理人员只需要维护对应的组件、布局和模板就行了。
总结
上述几点就是大圣魔方的一个总纲,其中大部分功能已经实现了,还有一小部分处于开发之中(标准化UI组件、自助生成可视化报表)。目前大圣魔方已经上线将近一年了,支持了内部众多业务,后续我们还会在UI易用性、星型模型、配置简化、元数据同步等方面做一些提高。
招聘
最后插播一个招聘广告,有对BI工具开发感兴趣的可以发邮件给 fuyishan@meituan.com
