

智能投放系统之场景分析最佳实践
背景
美团点评作为业内最大的O2O的平台,以短信/push作为运营手段触达用户的量级巨大,每日数以千万计。
美团点评线上存在超过千万的POI,覆盖超过2000城市、2.5万个后台商圈。在海量数据存在的前提下,实时投放的用户在场景的选择上存在一些困难,所以我们提供对场景的颗粒化查询和智能建议,为用户解决三大难题:
- 我要投放的区域在哪,实时和历史的客流量是什么样的?
- 在我希望投放的区域历史和现在都发生过什么活动,效果是什么样的?
- 这个区域是不是适合我投放,系统建议我投放哪里?
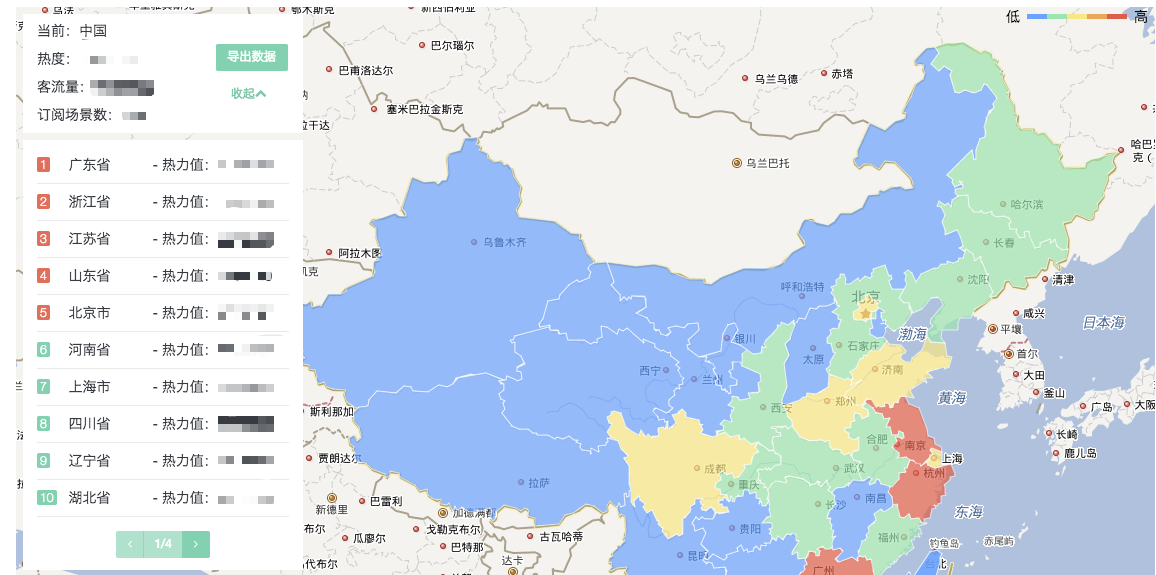
如图1所示,整个产品致力于解决以上三大问题,能够为运营在活动投放前期,提供有效的参考决策依据。
挑战
- 场景查询器需要展示的数据分为多种,所以数据过滤和组装的时间,严重依赖于基础数据量。但是随着维度的下钻,基础数据量巨大,所以导致实时计算数据的响应时间无法忍受。
- 数据来源均是RPC服务,需要调用的服务多种多样,每一项服务的响应时间都会影响最终的结果返回,难以提供前端接口的响应时间。
- 需要组装的数据各种各样,没有统一的数据模型,造成代码耦合度高,后期难以维护针对上面的挑战,我们给出如下的解决方案。
总体方案
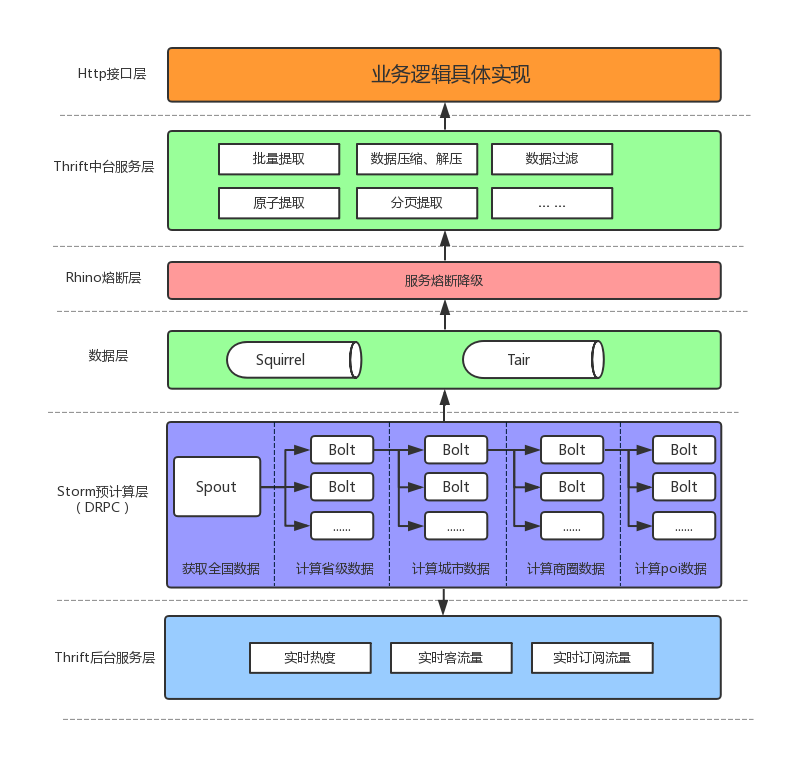
如图2所示,我们的总体架构是分层设计的,最底层都是各类服务,再上层是预计算层和数据层,预计算层的作用很明显,是连接服务和数据的核心层,通过拉取后台服务的各类数据然后预计算形成数据层。再往上是中台服务层,包含有核心功能是服务熔断降级,以及通用服务,为具体业务逻辑提供统一的服务,最上层便是具体的业务逻辑了,对应具体场景和需求。
后台服务层
该层均是Thrift的RPC服务,提供各种投放的反馈数据。
数据组装
后台服务层数据特点是数据分散,结果多样。数据组装是对多个服务调用返回的结果,进行过滤组合。
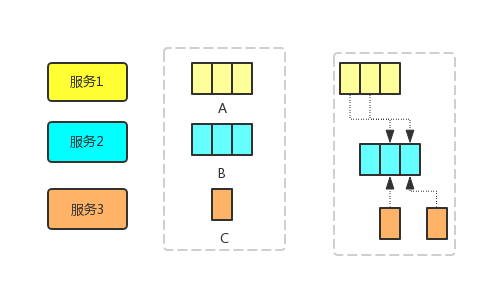
如图3所示,服务1、2、3分别用黄色、蓝色、棕色表示,A 、B、C均是调用对应服务返回的数据,并且A、B的数据格式是列表,C是单个数据。最后一个虚线框,代表数据组装算法,A和B的列表取交集,结果是长度为2的列表,然后再依次调用服务3,单个获取数据C。
数据组装痛点
- 过程繁琐,如取交集,单个组装等等,组装时间受数据量影响较大。
- 组装过程中,混合着大量的服务调用,组装时间受服务响应时间影响较大。
后台服务层重点在于提供数据,保证服务的可用性。但是在组装过程中遇到以上痛点,导致出现请求响应时间长,用户体验差等问题。规避此类问题的主要方法是将服务调用数据提前组合计算好进行存储,即数据预计算。
预计算层
主要作用在于提前计算数据,快速响应请求,构建过程依次为数据建模、构建计算模式。该层主要包含以下核心功能。
- 构建通用的数据模型,使上层控制和处理,更加高效。
- 保证计算速度的同时,计算大量基础数据。
- 为了保证数据的实时性,实现高密度并行计算。
数据模型
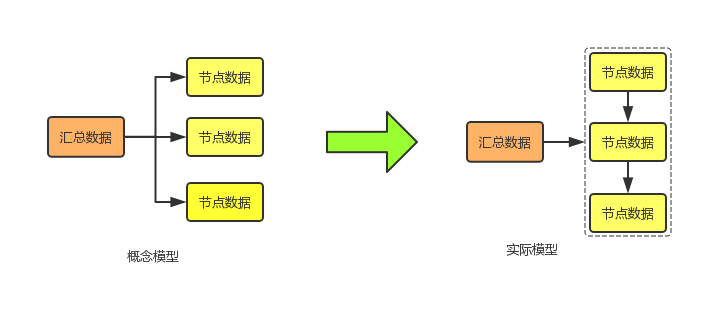
在场景查询器中,为前端提供的数据普遍都是上下级数据,比如页面要展示全国汇总数据,同时会级联展示下属各省数据,如果展示省级汇总数据,那么同时级联展示下属各地级市数据。通过分析业务需求,发现需要的数据,大多是分上下级的这种级联数据。经过抽象,数据模型设计为树形结构,如图4,左侧为概念模型,树的高度只有两层,根节点为汇总数据,叶子节点为地理等级维度下钻的数据;右侧为实际使用的模型,因为底层维度的基数比较大,不利于下级数据的遍历、筛选和分页,所以实际使用中,下级节点数据以一个列表存储。节点可以存储若干指标,具体类型根据地理维度而定。该模型的特点如下:首先支持地理维度继续下钻,其次在后台服务支持的情况下,可以对历史数据做预计算。
数据存储和获取
有了数据模型,需要确定一个高效的数据存储和数据定位的方式,因为结果数据大多是非半结构化数据,而且低维度的的数据量数据量较大,所以采用NoSQL来存储数据。
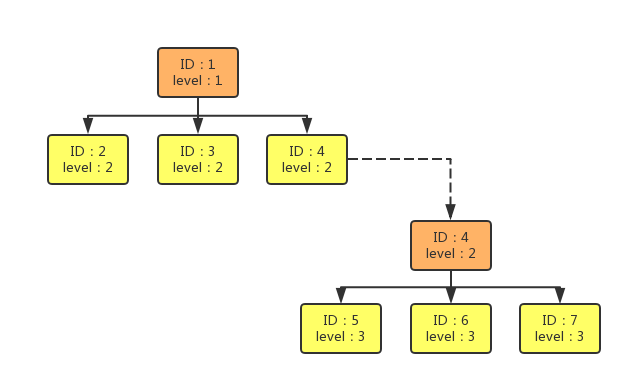
如图5所示,ID表示地理维度值,level表示地理维度等级,数据节点(包含根和叶子节点)以ID+level为Key,转化为树形JSON格式数据存储,通过ID+level可以唯一获取到一个数据,在数据量不大的情况下,还可以通过级联获取下级模型,即图中虚线代表级联获取下级数据。
计算模式
在构建的数据模型基础上,该层最核心便是预计算模式,从业务需求出发,数据需要在地理等级这个维度不断下钻,从全国开始,一直下钻到POI级别,每个级别单独分层计算,然后存储计算结果。
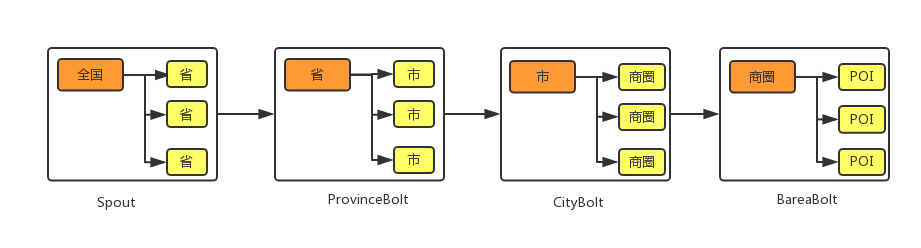
如图6所示,每一个矩形代表一级维度的计算,从左到右依次进行维度下钻,从全国的数据依次计算到商圈,计算分层每层单独计算。
实现方式
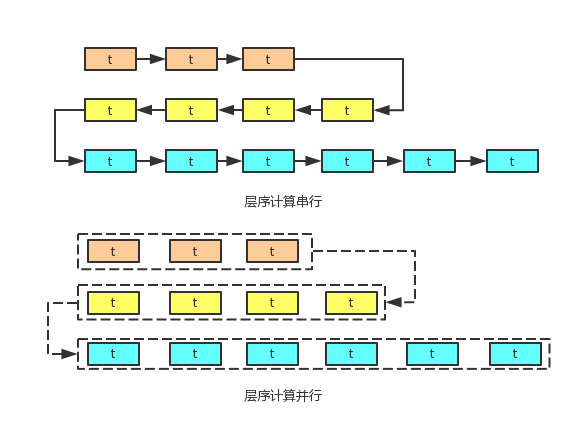
如图7所示,是计算模式的两种实现方式,上半部分是串行层序计算,下半部分是并行层序计算。每部分从上到下分不同颜色区分不同的计算层次。每个矩形对应一个具体ID的计算,t代表计算时间,这里假设所有计算单元的计算时间都相同,方便对比计算时间。
1)串行层序计算
如图7,普通的串行计算,使用单线程计算,从上到下一层一层计算,这类计算的的痛点有两处,第一,是时间复杂度的,每个计算单元的计算时间都会累计,如计算第一层的时间为3t,第二层为4t,第三层为6*t,总计耗时13t。第二,是空间复杂度的,因为数据均是调用后台服务获取,计算一层的同时,需要把下级的数据都存储起来,在计算下层时候,再遍历数据计算。
2)并行层序计算
依赖于Apache Storm计算框架,将数据抽象成为流,然后通过不同的Bolt,分别计算不同维度的数据。每一级Bolt首先处理数据,然后将下级数据流入下一级Bolt。同时随着维度的下钻,计算的数据量变得越来越大,通过增加Bolt的并发度,加速计算。在预计算的过程中,主要利用了Storm高速数据分发和高密度并行计算的特性,规避了串行计算的痛点,首先时间复杂度大幅度降低,如图7所示,因为可以并行计算,所以每一层的时间只花费t,那么总耗时为3*t,当然这样估算是不准确的,因为没必要在一层所有数据都计算完,才发射数据,可以在每一个计算单元运行完毕,就发射数据。这样就可以形成上下级数据计算流水线,进一步压缩计算时间。其次,空间复杂度大幅度降低,在Storm中,不需要保存下级数据,因为数据是不断流动的,计算完毕就会被发射到下级Bolt。为此,本文采用Storm做预计算。计算拓扑结构如图8。
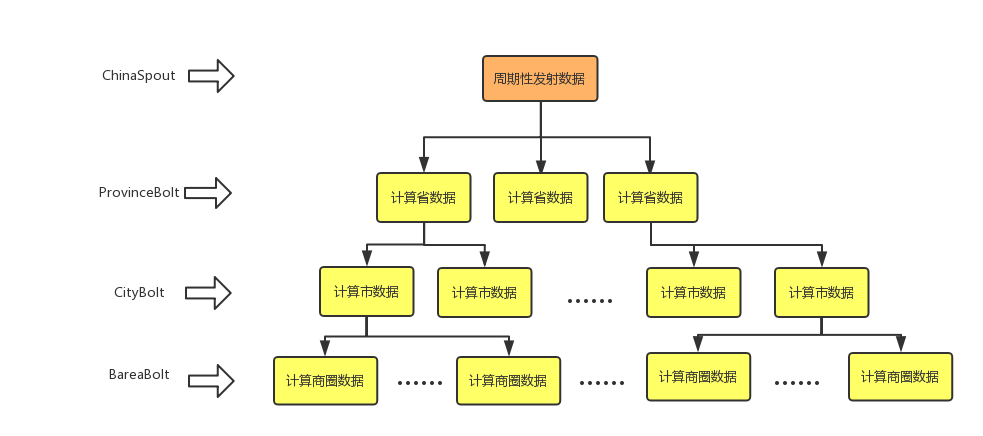
如图8所示,数据源头(ChinaSpout)只有一个,该Spout内首先计算全国到省的数据,包括全国汇总数据以及省一级的数据,然后立刻将所有省级数据流入下层的ProvinceBolt,这一层应该考虑增加并发度,因为省到市一级的数据量级开始扩大,设置并发度为40,在计算完省到市级数据之后,数据开始流入CityBolt,这一层到市级数据,并发度可以再扩大,目前配置为300,计算完毕之后,数据流入最后一层BareaBolt,计算商圈到POI级别的数据。各级Bolt预计算产生的结果数据,都会存入数据层。存储时遇到一个问题,在计算商圈到POI级别的数据时候,发现POI的量级比较大,不能直接存储。为了不影响数据模型的通用性,我们队POI级别的做了压缩,然后再做存储。为了保障数据的实时性,数据源会周期性产生数据流,更新预计算数据,其实这是Storm一类计算模式-----DRPC,数据源头就是发射的参数,Storm的各级Bolt承担运算。
该层解决的最大问题,是计算速度慢的问题,通过高密度的并发计算,降低重复数据过滤,大量数据组合,以及批量数据获取慢对响应时间的影响。
数据层
预计算之后的数据需要存储,供业务逻辑使用,存储选型需要满足以下几点:
- 预计算产生的数据模型是树形结构,所以不适合关系型数据库
- 数据具有时效性,数据过期会带来脏数据
- 高密度并行计算,写入并发量大,需要保证写入速度
- 实现灾备,存储不可用时候,需要服务降级
为了满足以上几点要求,选用美团点评内部研发的公共KV存储组件Squirrel和Tair分别来做存储和灾备。其中,Squirrel是基于Redis Cluster的纯内存存储,squirrel 属于KV存储,具有写入、查询速度快,并发度高,支持数据丰富,时效好的特点。而Tair支持持久化,性价比更高,适合用来做灾备,当Squirrel不可用时,使用Tair提供服务。
熔断层
预计算过程中,为了实现灾备,还需要使用熔断技术实现服务降级。熔断虽然在上层控制,严格来说应该属于数据层。
熔断技术选用公共组件Rhino(美团点评自研的稳定性保障平台,比Hystrix更加轻量、易用及可控,提供故障模拟、降级演练、服务熔断、服务限流等功能),主要作用是:
- a. 保护服务,防止服务雪崩
- b. 及时熔断,保障服务稳定
- c. 提供多种降级策略,灵活适配服务场景
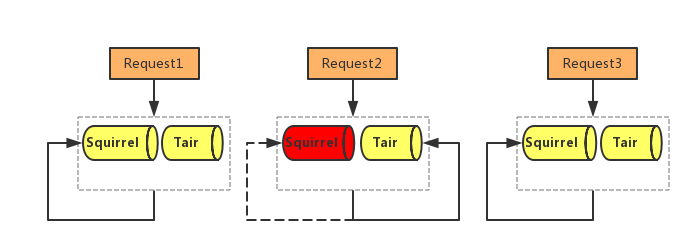
如图9所示,虚线框,代表Rhino控制的区域,request1到来的时候,squirrel没有问题,正常提供服务。request2 到来的时候,访问squirrel发生异常(超时、异常等),请求被切换到tair。在squirrel恢复的过程中,Rhino会心跳请求squirrel,验证服务可用性。request3请到来squirrel此刻已经恢复正常,由于Rhino会周期检测,所以请求再次被切换到squirrel上恢复正常。
中台服务层
数据准备好之后,还不能被业务逻辑直接使用,需要提供统一的服务,应对多变的业务逻辑。该层主要解决如下问题:
- 数据模型修改对业务逻辑有影响,数据服务需对上层具体业务逻辑透明
- 业务逻辑对数据有部分通用操作,需要抽象通用操作,防止数据业务紧耦合
- 存储不可用的时候,需要服务熔断和降级,降低对业务逻辑的影响
- 服务扩展增强能力,不能影响正常业务逻辑
该层对外提供RPC服务,直接处理数据模型,提供数据分页、数据压缩、数据解压、数据筛选、数据批量提取以及数据原子提取 等功能,基本覆盖了大部分对数据的操作,使得业务逻辑更加简单。提取数据的时候,加入Rhino实现服务熔断和降级,为业务逻辑层提供稳定可靠的服务。因为该层直接操作模型数据,所以即使数据模型有改动,也不会对业务逻辑造成影响,大大降低数据和业务的耦合。另外该层支持服务横向扩展,在消费者大量增加的情况下,仍然能保证服务可靠运转。
通过一系列的抽象和分层,最终业务逻辑直接使用简单的服务接口就可以实现,客户端的响应从最开始的十几秒,提升到1秒以内,并且数据和代码之间的耦合大幅度降低,对于后面的业务变化,只需要修改数据模型,增量提供若干中台服务接口,即可满足需求,大大降低了开发难度。
作者简介
- 张腾,美团点评系统开发工程师,2016年毕业于西安电子科技大学,同年加入招银网络科技,从事系统开发以及数据开发工作。2017年加入美团点评数据中心,长期从事BI工具开发工作。
招聘信息
最后插播一个招聘广告,有对数据产品工具开发感兴趣的可以发邮件给 fuyishan@meituan.com。
我们是一群擅长大数据领域数据工具,数据治理,智能数据应用架构设计及产品研发的工程师。
