

卫星系统——酒店后端全链路日志收集工具介绍
背景
随着酒店业务的高速发展,我们为用户、商家提供的服务越来越精细,系统服务化程度、复杂度也逐渐上升。微服务化虽然能够很好地解决问题,但也有副作用,比如,问题定位。
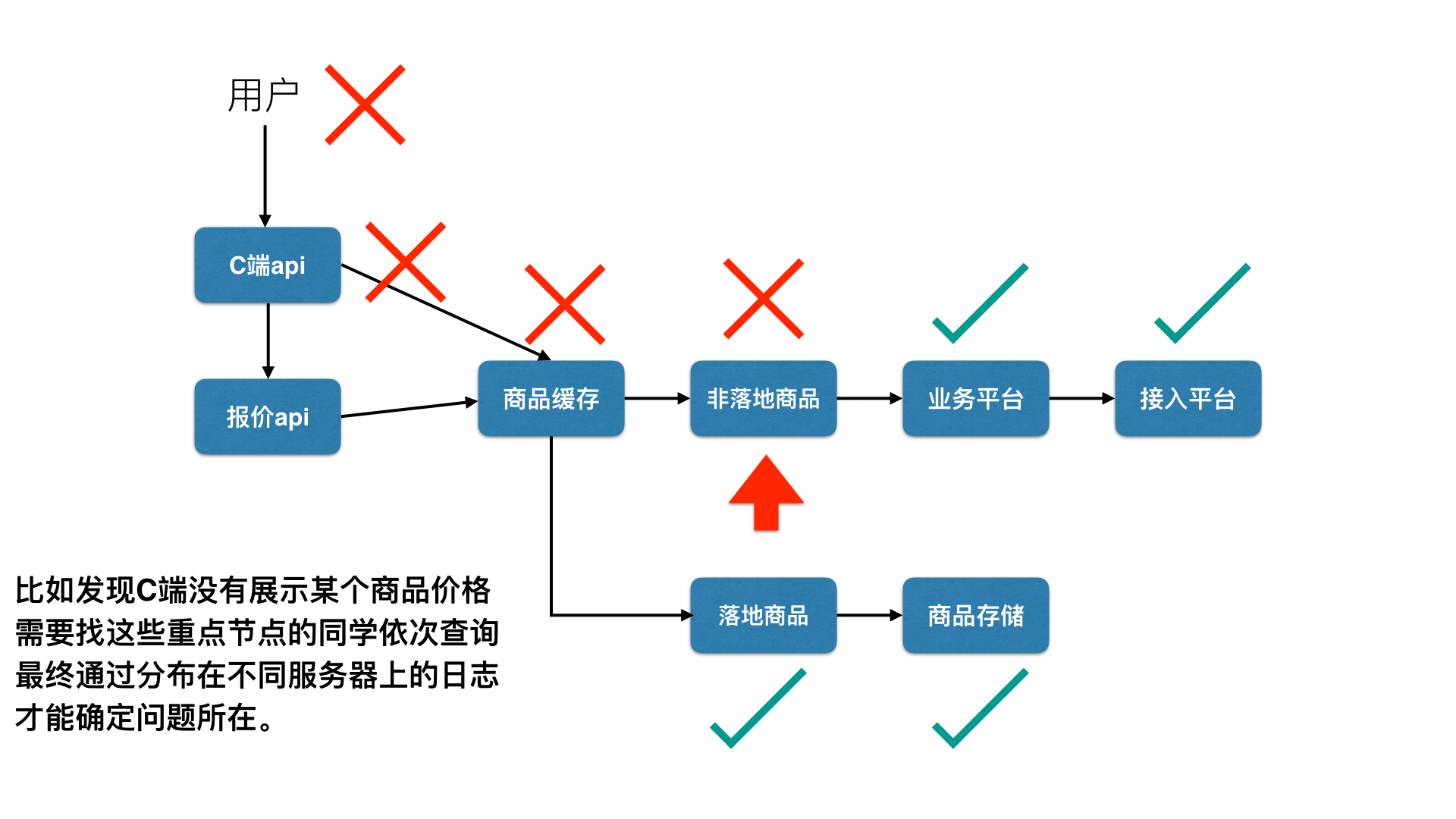
每次问题定位都需要从源头开始找同事帮我人肉查日志,举一个简单的例子:
“这个详情页的价格是怎么算出来的?”
一次用户酒店可订空房页(POI详情页)访问,流量最多需要经过73个服务节点。查问题的时候需要先后找4~5个关键节点的同学帮我们登录十多个不同节点的机器,查询具体的日志,沟通成本极大,效率很低。
为了解决这个问题,基础架构的同学提供了MTrace(详情可以参考技术博客:《分布式会话跟踪系统架构设计与实践》)协助业务方排查长链路问题。
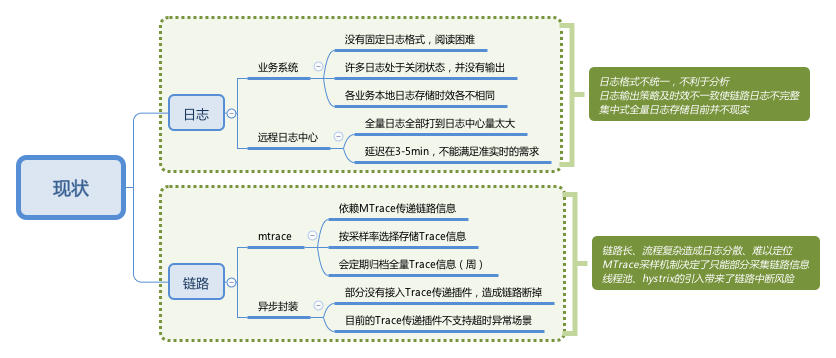
但是与此同时,还有许多不确定性因素,使问题排查过程更加艰难,甚至无果而终:
- 各服务化节点存储日志的时间长度不一致;
- 有的服务节点,因为QPS过高,只能不打或者随机打印日志,会导致最终查问题的时候,线索因为没日志断掉;
- 有的服务节点,使用了异步逻辑(线程池、Hystrix、异步RPC等)导致日志中缺失Trace ID,无法关联在一起;
- 各服务节点的采样率不一样,链路数据的上报率也是随机性的,线索容易断掉;
- MTrace上只有链路信息,没有关联各服务节点的日志信息;
- 动态扩容节点上的日志,缩容后无法找到。
总结起来如图所示:
目标
我们的核心诉求有两个:
- 根据用户行为快速定位到具体的Trace ID,继而查询到这次服务调用链路上所有节点的日志;
- 查询的实时性要能做到准实时(秒级输出),相关链路日志要在独立外部存储系统中保存半年以上。
然后我们对诉求做了进一步的拆分:
- 全量打日志不现实,需要选择性打,打价值最高部分的日志;
- 链路数据需要全服务节点都上传,避免因为异步化等原因造成链路数据中断不上传;
- 接入方式尽量简单,避免所有服务节点都需要修改具体业务代码来接入。最好是能通过日志拦截的方式,其它保持透明;
- 日志格式化,该有的字段(AppKey、hostname、IP、timestamp等)不需要业务RD反复输入,自动补齐;
- 在不阻塞原有业务操作的情况下,做到准实时展示链路、日志;
- 链路数据和日志数据存储,不依赖各服务节点,需要在独立的存储系统上存储半年以上。
系统
搞清了核心诉求后,我们针对性地做了许多调研,最终定了一个系统的整体设计方案,这就是目前已经上线并实践已久的美团点评酒店「卫星系统」。
下面,我们就来对系统做详细介绍,包括一些核心细节点。
架构
如下图所示,卫星系统从横向分为链路和日志两个部分。
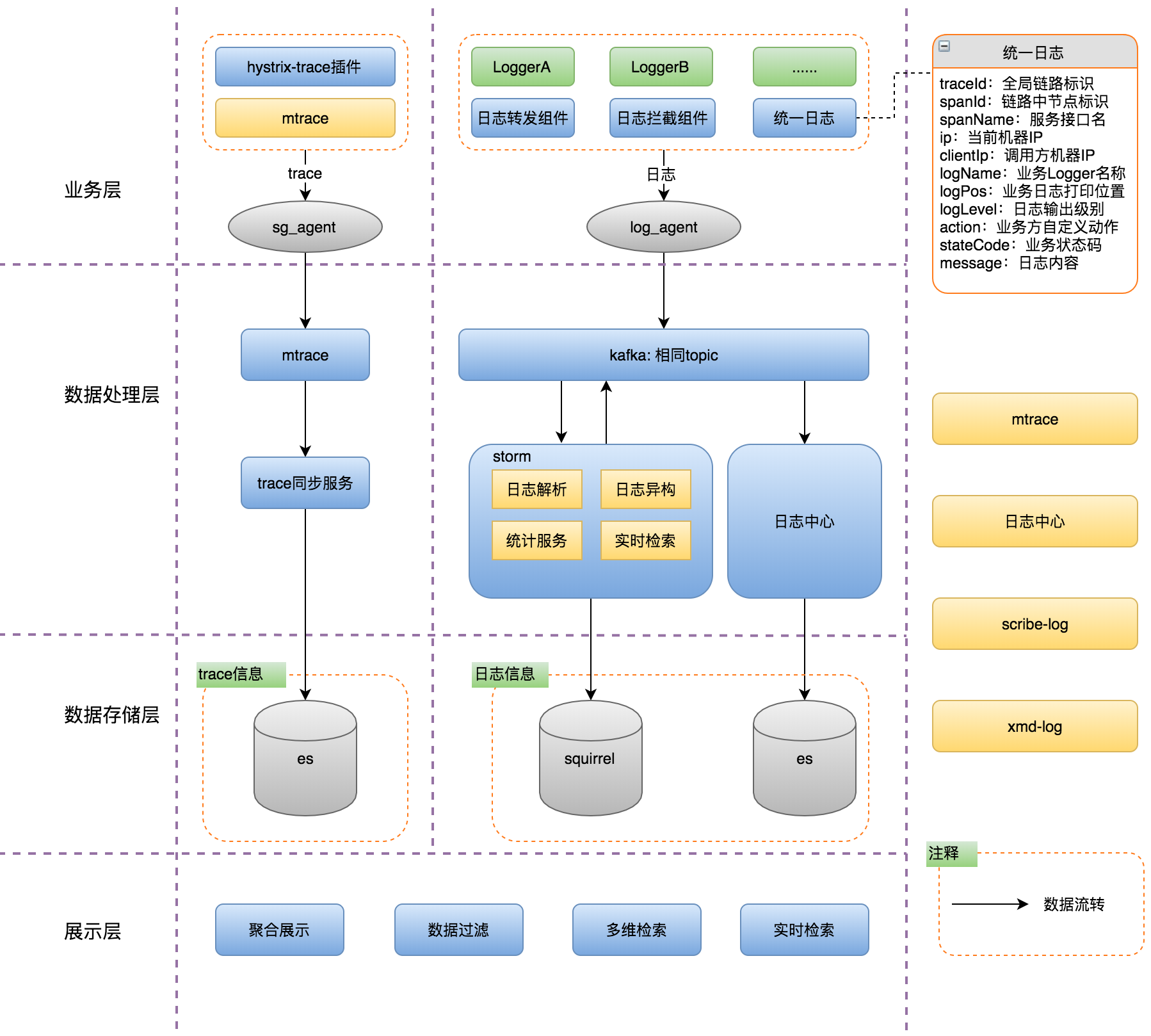
链路部分是以MTrace为基础,用支持超时fallback下Trace信息传递的Hystrix-Trace插件来覆盖全部场景,保证链路被完整采集。
日志部分在接入端有三大核心步骤,首先是依托于日志拦截组件实现对业务代码零侵入的情况下收集系统中所有日志内容,然后根据统一日志规范对日志进行格式化处理,最后通过基于logcenter日志传输机制实现日志到Kafka的传输。
从纵向又分为:
- 业务接入层,根据策略采集Trace与业务日志;
- 数据处理层,通过storm流式处理日志信息;
- 数据存储层,用于支持实时查询的Squirrel(美团点评Redis集群)与持久存储的ES(ElasticSearch),以及面向用户的展示层。
日志采样方案
接入端是所有数据之源,所以方案设计极为关键。要解决的问题有:采集策略、链路完整性保障、日志拦截、日志格式化、日志传输。
有的业务单台机器每天日志总量就有百G以上,更有不少业务因为QPS过高而选择平时不打印日志,只在排查问题时通过动态日志级别调整来临时输出。所以,我们在最初收集日志时必须做出取舍。经过分析,发现在排查问题的时候,绝大多数情况下发起人都是自己人(RD、PM、运营),如果我们只将这些人发起的链路日志记下来,那么目标日志量将会极大减少,由日志量过大而造成的存储时间短、查询时效性差等问题自然得到解决。
所以我们制定了这样的采集策略:
通过在链路入口服务判断发起人是否满足特定人群(住宿事业部员工)来决定是否进行日志采集,将采集标志通过MTrace进行全链路传递。这样就能保证链路上所有节点都能行为一致地去选择是否进行日志上报,保证链路上日志的完整性。
日志拦截
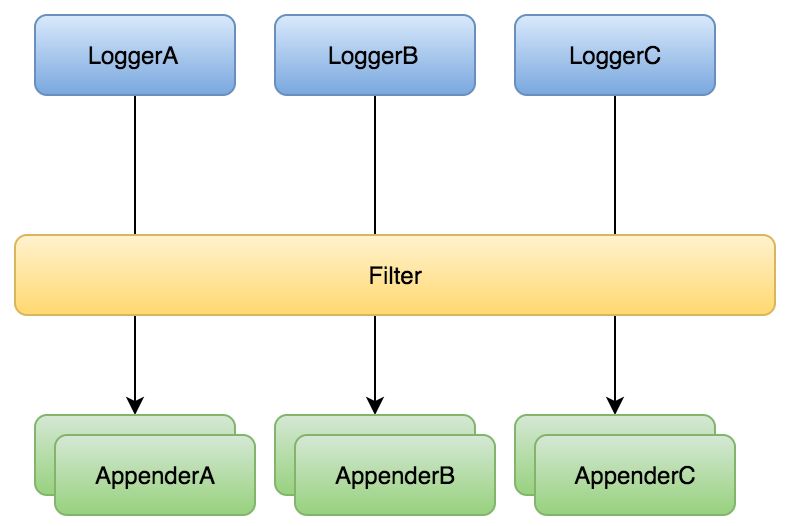
作为核心要素的日志,如何进行收集是一个比较棘手的问题。让业务方强制使用我们的接口进行日志输出会带来许多麻烦,一方面会影响业务方原有的日志输出策略;另一方面,系统原有的日志输出点众多,涉及的业务也五花八门,改动一个点很简单,但是全面进行改动难保不会出现未知影响。所以,需要尽可能降低对接入方代码的侵入。
由于目前酒店核心业务已全面接入log4j2,通过研究,发现我们可以注册全局Filter来遍历系统所有日志,这一发现,使我们实现了代码零改动的情况下收集到系统所有日志。
日志格式化
业务系统输出的日志格式不一,比如有的没有打印TraceID信息,有的没有打印日志位置信息从而很难进行定位。这主要带来两方面的问题,一方面不利于由人主导的排查分析工作,另一方面也不利于后续的系统优化升级,比如对日志的自动化分析报警等等。
针对这些问题,我们设计了统一日志规范,并由框架完成缺失内容的填充,同时给业务方提供了标准化的日志接口,业务方可以通过该接口定义日志的元数据,为后续支持自动化分析打下基础。
由框架填充统一日志信息这一过程利用到了log4j2的Plugins机制,通过Properties、Lookups、ContextMap实现业务无感知的操作。
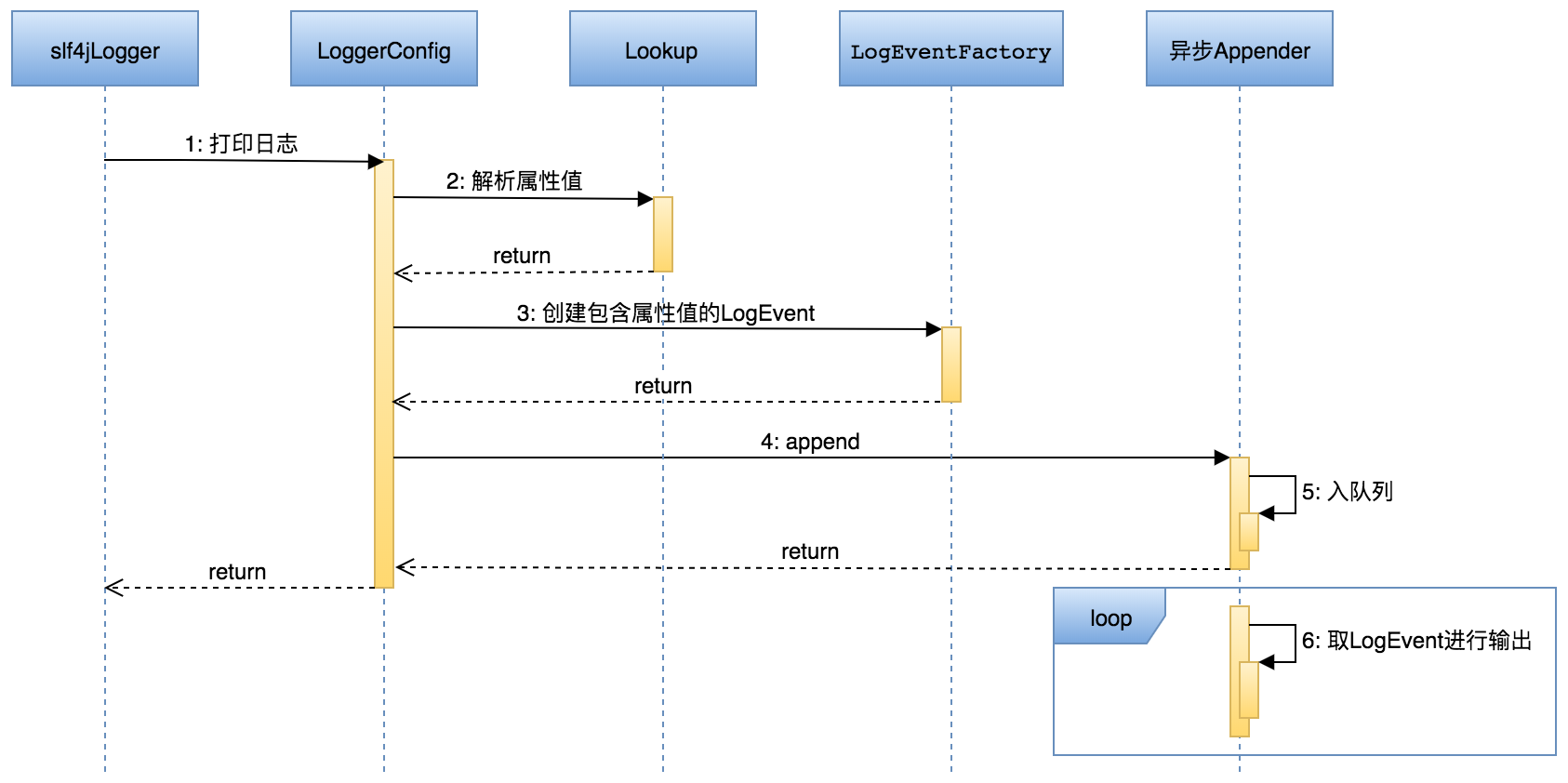
日志处理
我们在最终的日志传输环节利用了日志中心的传输机制,使用日志中心的ScribeAppender实现日志传输至本地agent,然后上报到远端Kafka,这样设计有几点好处:
- 依赖公司成熟的基础服务相对而言更可靠、更稳定,同时也省去了自己搭建服务、保证服务安全这一过程;
- 可以将日志直接转存至日志中心ES做持久化存储,同时支持快速灵活的数据检索;
- 可以通过Storm对日志进行流式处理,支持灵活的系统扩展,比如:实时检索、基于日志的实时业务检查、报警等等,为后续系统扩展升级打下基础。
我们的数据处理逻辑全部在Storm进行处理,主要包含日志存储Squirrel(美团点评内部基于Redis Cluster研发的纯内存存储)、实时检索与Trace同步。
目前日志中心ES能保证分钟级别实时性,但是对于RD排查问题还是不够,必须支持秒级别实时性。所以我们选择将特定目标用户的日志直接存入Squirrel,失效时间只有半小时,查询日志时结合ES与Squirrel,这样既满足了秒级别实时性,又保证了日志量不会太大,对Squirrel的压力可以忽略不计。
我们的系统核心数据有链路与日志,链路信息的获取是通过MTrace服务获得,但是MTrace服务对链路数据的保存时间有限,无法满足我们的需求。所以,我们通过延时队列从MTrace获取近期的链路信息进行落地存储,这样就实现了数据的闭环,保证了数据完整性。
链路完整性保障
MTrace组件的Trace传递功能基于ThreadLocal,而酒店业务大量使用异步化逻辑(线程池、Hystrix),这样会造成传递信息的损失,破坏链路完整性。
一方面,通过Sonar检查和梳理关键链路,来确保业务方使用类似transmittable-thread-local中的ExecutorServiceTtlWrapper.java、ExecutorTtlWrapper.java的封装,来将ThreadLocal里的Trace信息,也传递到异步线程中(前文提到的MTrace也提供这样的封装)。
另一方面,Hystrix的线程池模式会造成线程变量丢失。为了解决这个问题,MTrace提供了Mtrace Hystrix Support Plugin插件实现跨线程调用时的线程变量传递,但是由于Hystrix有专门的timer线程池来进行超时fallback调用,使得在超时情况下进入fallback逻辑以后的链路信息丢失。
针对这个问题,我们深入研究了Hystrix机制,最终结合Hystrix Command Execution Hook、Hystrix ConcurrencyStrategy、Hystrix Request Context实现了覆盖全场景的Hystrix-Trace插件,保障了链路的完整性。
HystrixPlugins.getInstance().registerCommandExecutionHook(new HystrixCommandExecutionHook() {
@Override
public <T> void onStart(HystrixInvokable<T> commandInstance) {
// 执行command之前将trace信息保存至hystrix上下文,实现超时子线程的trace传递
if (!HystrixRequestContext.isCurrentThreadInitialized()) {
HystrixRequestContext.initializeContext();
}
spanVariable.set(Tracer.getServerSpan());
}
@Override
public <T> Exception onError(HystrixInvokable<T> commandInstance, HystrixRuntimeException.FailureType failureType, Exception e) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
return e;
}
@Override
public <T> void onSuccess(HystrixInvokable<T> commandInstance) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
}
});
HystrixPlugins.getInstance().registerConcurrencyStrategy(new HystrixConcurrencyStrategy() {
@Override
public <T> Callable<T> wrapCallable(Callable<T> callable) {
// 通过自定义callable保存trace信息
return WithTraceCallable.get(callable);
}
});
效果展示
比如以排查一次用户点击某POI详情页的TraceID为例子:
我们可以看到他在MTrace中的调用链路是这样的:
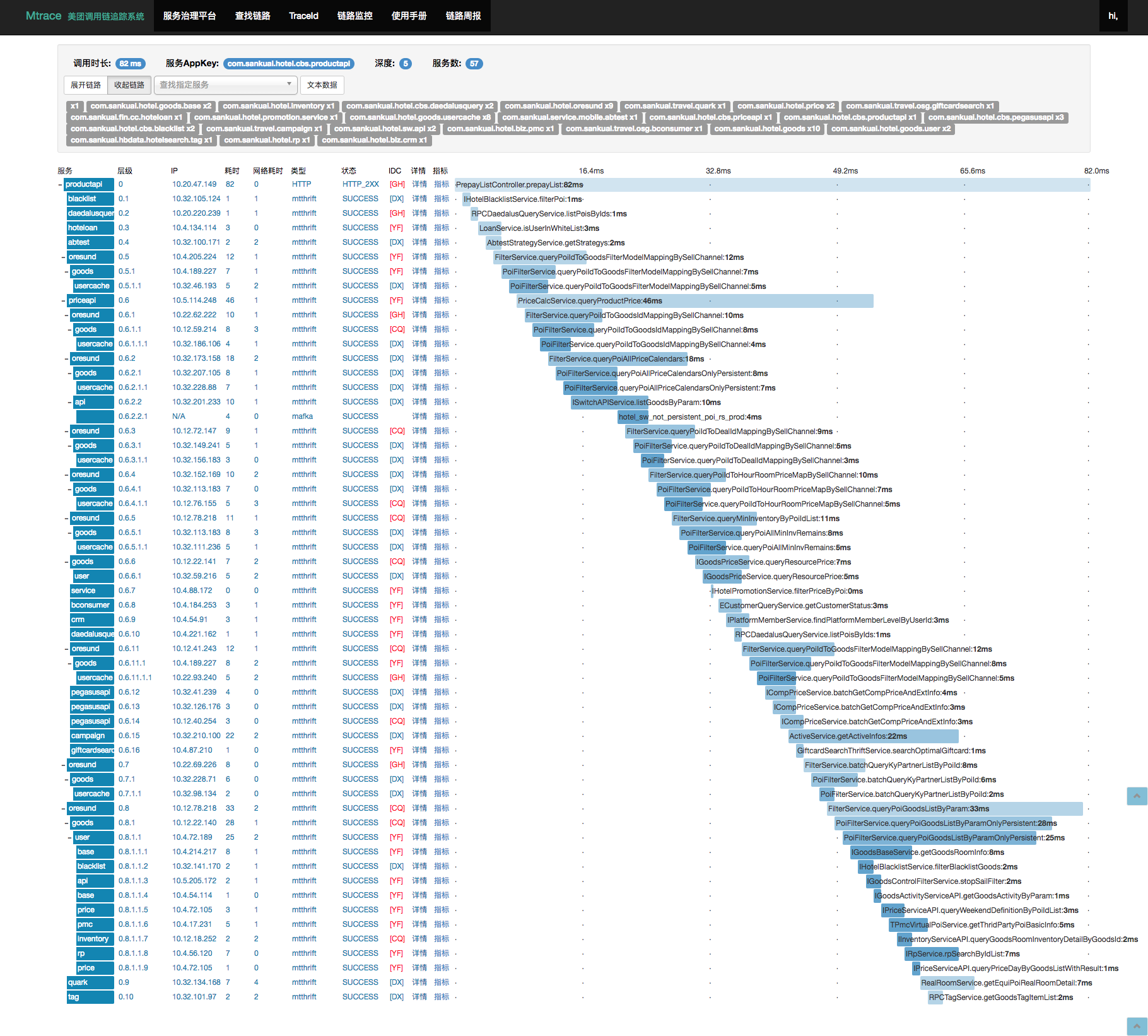
在卫星系统中,展示为如下效果:
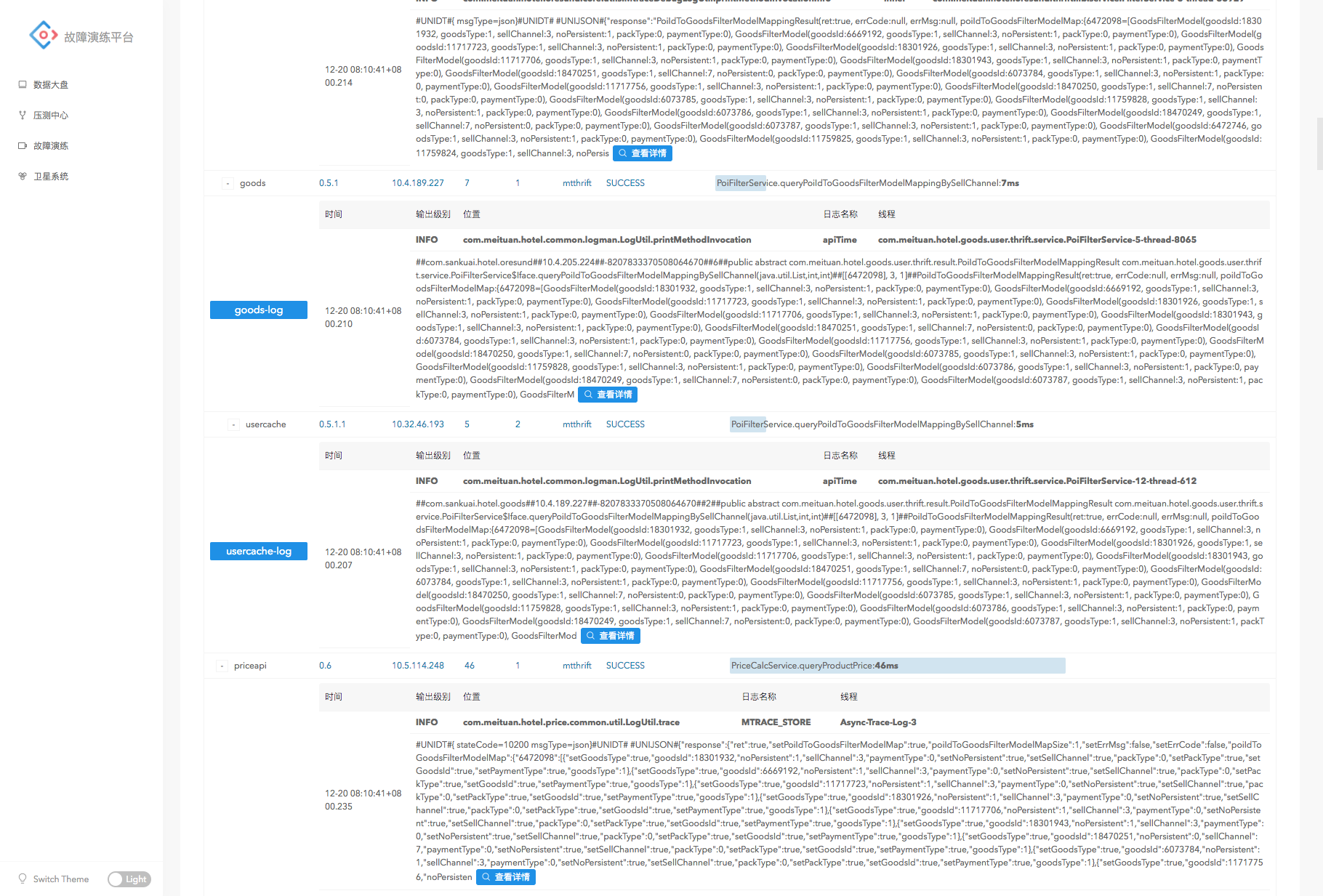
可见,在保留了链路数据的基础上,系统还将全链路节点日志聚合到了一起,提升了排查效率。
后续规划
目前,系统还处于初级阶段,主要用来解决RD在排查问题时的两大痛点:日志信息的不完整与太分散,现在已经满足了这一需求。但是,全链路日志系统能做的不止这些,后续的主要规划有如下几方面:
- 支持多链路日志关联搜索,比如一次列表页刷新与后续的详情页展示,虽然链路是多个但是实际处在一个关联的场景中。支持关联搜索就可以可以将日志排查目标从单个动作维度扩展到多动作组成的场景维度。
- 支持业务方自定义策略规则进行基于日志的自动化业务正确性检查,如果检查出问题可以直接将详细信息通知相关人员,实现实时监测日志、实时发现问题、实时通知到位,免去人工费时费力的低效劳动。
作者简介
- 亚辉,2015年加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组。
- 曾鋆,2013年加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组。
招聘信息
最后发个广告,美团点评酒旅事业群技术研发部酒店后台研发组长期招聘Java后台、架构方面的人才,有兴趣的同学可以发送简历到xuguanfei#meituan.com。
