

使用TensorFlow训练WDL模型性能问题定位与调优
简介
TensorFlow是Google研发的第二代人工智能学习系统,能够处理多种深度学习算法模型,以功能强大和高可扩展性而著称。TensorFlow完全开源,所以很多公司都在使用,但是美团点评在使用分布式TensorFlow训练WDL模型时,发现训练速度很慢,难以满足业务需求。
经过对TensorFlow框架和Hadoop的分析定位,发现在数据输入、集群网络和计算内存分配等层面出现性能瓶颈。主要原因包括TensorFlow数据输入接口效率低、PS/Worker算子分配策略不佳以及Hadoop参数配置不合理。我们在调整对TensorFlow接口调用、并且优化系统配置后,WDL模型训练性能提高了10倍,分布式线性加速可达32个Worker,基本满足了美团点评广告和推荐等业务的需求。
术语
- TensorFlow - Google发布的开源深度学习框架
- OP - Operation缩写,TensorFlow算子
- PS - Parameter Server 参数服务器
- WDL - Wide & Deep Learning,Google发布的用于推荐场景的深度学习算法模型
- AFO - AI Framework on YARN的简称 - 基于YARN开发的深度学习调度框架,支持TensorFlow,MXNet等深度学习框架
TensorFlow分布式架构简介
为了解决海量参数的模型计算和参数更新问题,TensorFlow支持分布式计算。和其他深度学习框架的做法类似,分布式TensorFlow也引入了参数服务器(Parameter Server,PS),用于保存和更新训练参数,而模型训练放在Worker节点完成。
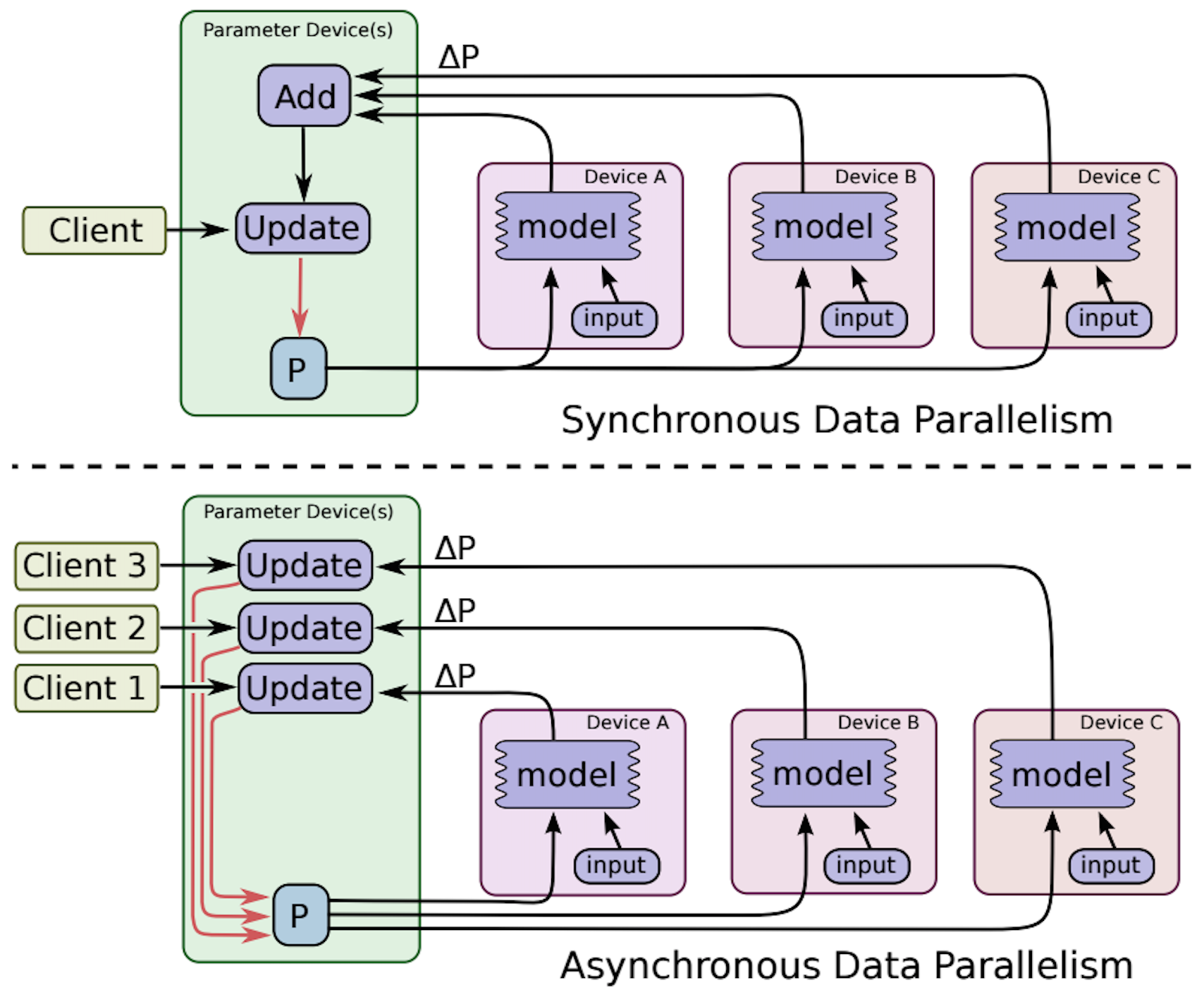
TensorFlow支持图并行(in-graph)和数据并行(between-graph)模式,也支持同步更新和异步更新。因为in-graph只在一个节点输入并分发数据,严重影响并行训练速度,实际生产环境中一般使用between-graph。
同步更新时,需要一个Woker节点为Chief,来控制所有的Worker是否进入下一轮迭代,并且负责输出checkpoint。异步更新时所有Worker都是对等的,迭代过程不受同步barrier控制,训练过程更快。
AFO架构设计
TensorFlow只是一个计算框架,没有集群资源管理和调度的功能,分布式训练也欠缺集群容错方面的能力。为了解决这些问题,我们在YARN基础上自研了AFO框架解决这个问题。
AFO架构特点:
- 高可扩展,PS、Worker都是任务(Task),角色可配置
- 基于状态机的容错设计
- 提供了日志服务和Tensorboard服务,方便用户定位问题和模型调试
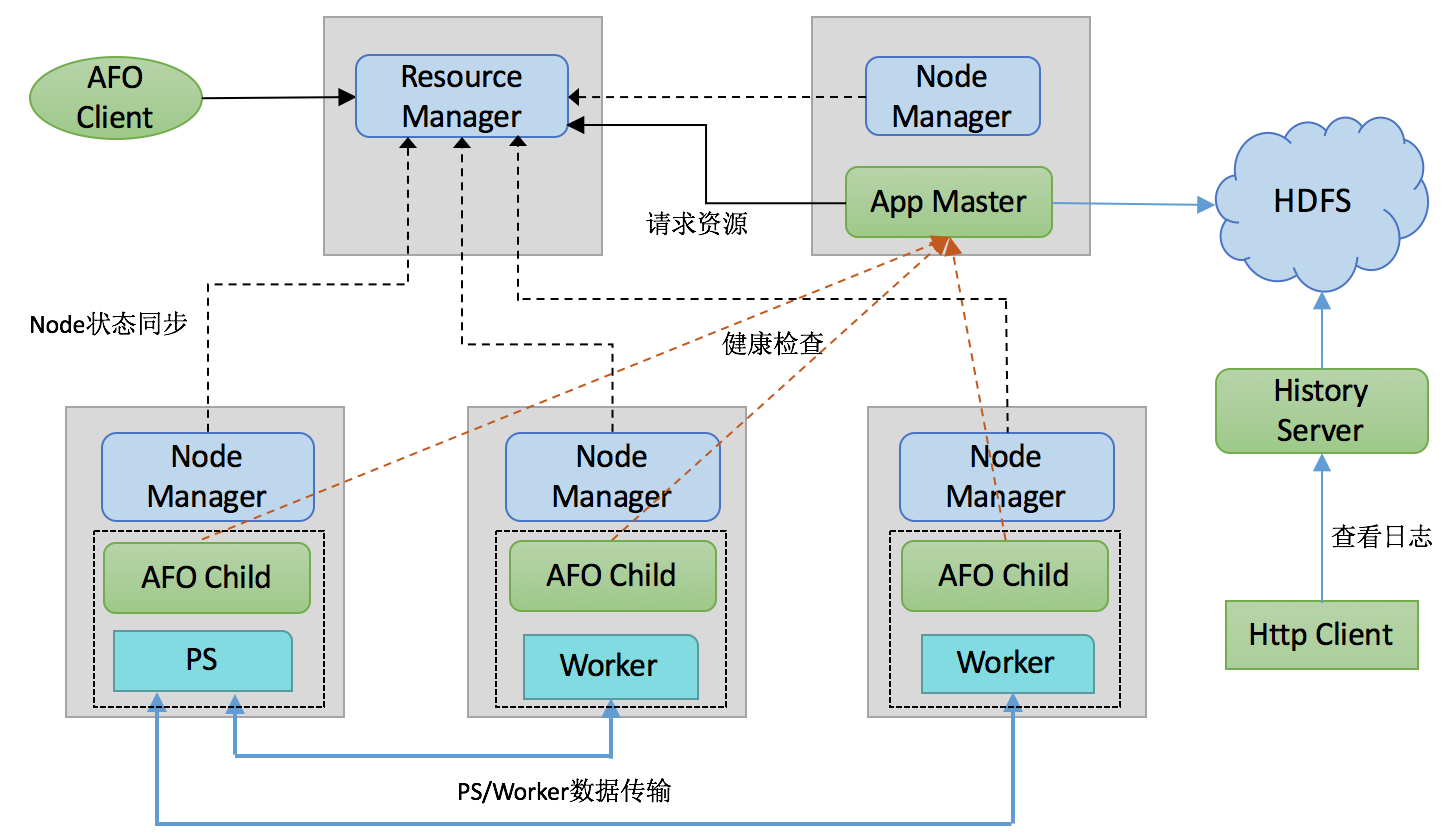
AFO模块说明:
- Application Master:用来管理整个TensorFlow集群的资源申请,对任务进行状态监控
- AFO Child:TensorFlow执行引擎,负责PS、Worker运行时管理和状态同步
- History Server:管理TensorFlow训练生成的日志
- AFO Client:用户客户端
WDL模型
在推荐系统、CTR预估场景中,训练的样本数据一般是查询、用户和上下文信息,系统返回一个排序好的候选列表。推荐系统面临的主要问题是,如何同时可以做到模型的记忆能力和泛化能力,WDL提出的思想是结合线性模型(Wide,用于记忆)和深度神经网络(Deep,用于泛化)。
以论文中用于Google Play Store推荐系统的WDL模型为例,该模型输入用户访问应用商店的日志,用户和设备的信息,给应用App打分,输出一个用户“感兴趣”App列表。
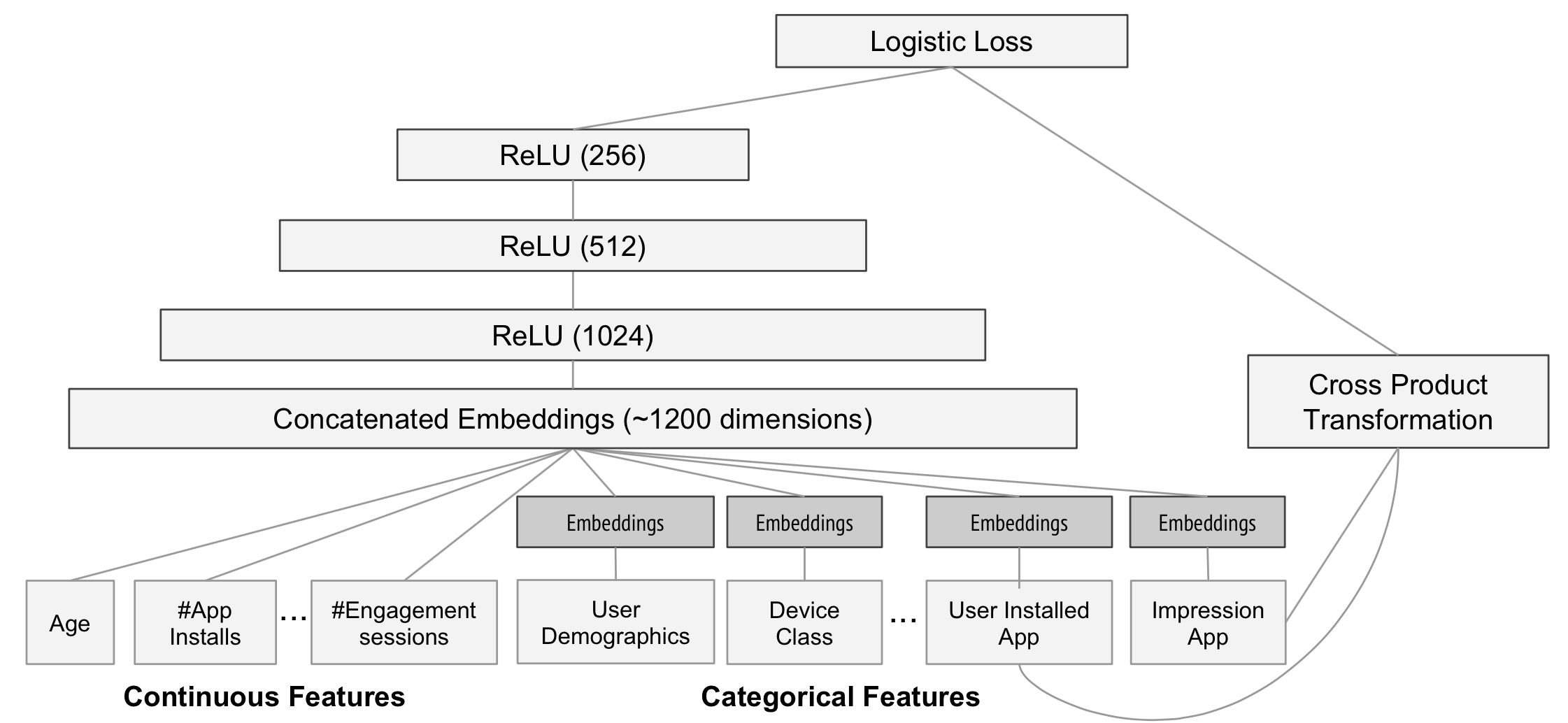
其中,installed apps和impression apps这类特征具有稀疏性(在海量大小的App空间中,用户感兴趣的只有很少一部分),对应模型“宽的部分”,适合使用线性模型;在模型“深的部分”,稀疏特征由于维度太高不适合神经网络处理,需要embedding降维转成稠密特征,再和其他稠密特征串联起来,输入到一个3层ReLU的深度网络。最后Wide和Deep的预估结果加权输入给一个Logistic损失函数(例如Sigmoid)。
WDL模型中包含对稀疏特征的embedding计算,在TensorFlow中对应的接口是tf.embedding_lookup_sparse,但该接口所包含的OP无法使用GPU加速,只能在CPU上计算,因此TensorFlow在处理稀疏特征性能不佳。不仅如此,我们发现分布式TensorFlow在进行embedding计算时会引发大量的网络传输流量,严重影响训练性能。
性能瓶颈分析与调优
在使用TensorFlow训练WDL模型时,我们主要发现3个性能问题:
- 每轮训练时,输入数据环节耗时过多,超过60%的时间用于读取数据。
- 训练时产生的网络流量高,占用大量集群网络带宽资源,难以实现分布式性能线性加速。
- Hadoop的默认参数配置导致glibc malloc变慢,一个保护malloc内存池的内核自旋锁成为性能瓶颈。
TensorFlow输入数据瓶颈
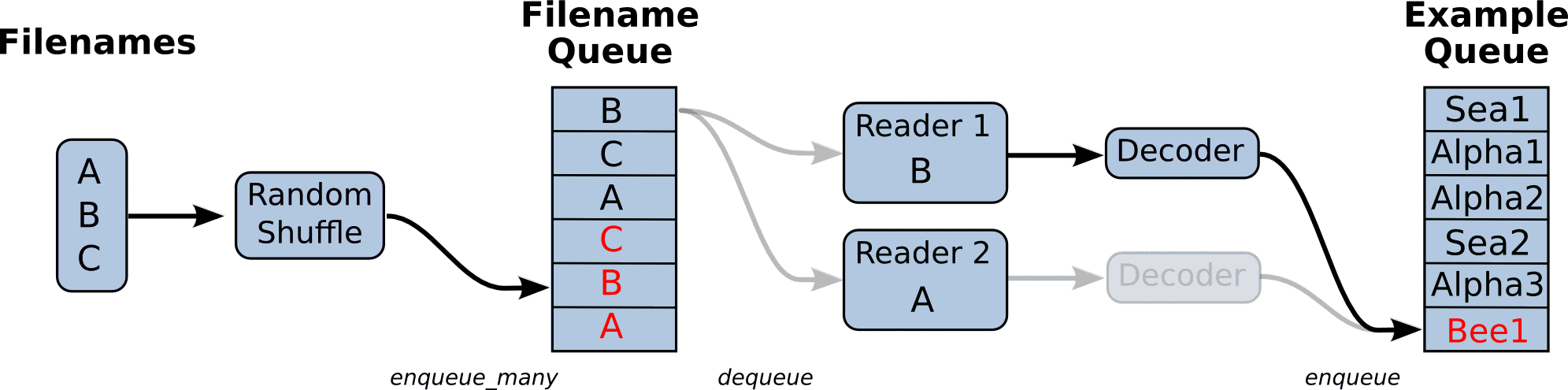
TensorFlow支持以流水线(Pipeline)的方式输入训练数据。如下图所示,典型的输入数据流水线包含两个队列:Filename Queue对一组文件做shuffle,多个Reader线程从此队列中拿到文件名,读取训练数据,再经过Decode过程,将数据放入Example Queue,以备训练线程从中读取数据。Pipeline这种多线程、多队列的设计可以使训练线程和读数据线程并行。理想情况下,队列Example Queue总是充满数据的,训练线程完成一轮训练后可以立即读取下一批的数据。如果Example Queue总是处于“饥饿”状态,训练线程将不得不阻塞,等待Reader线程将Example Queue插入足够的数据。使用TensorFlow Timeline工具,可以直观地看到其中的OP调用过程。
使用Timeline,需要对tf.Session.run()增加如下几行代码:
with tf.Session as sess:
ptions = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
_ = sess.run([train_op, global_step], options=run_options, run_metadata=run_metadata)
if global_step > 1000 && global_step < 1010:
from tensorflow.python.client import timeline
fetched_timeline = timeline.Timeline(run_metadata.step_stats)
chrome_trace = fetched_timeline.generate_chrome_trace_format()
with open('/tmp/timeline_01.json', 'w') as f:
f.write(chrome_trace)
这样训练到global step在1000轮左右时,会将该轮训练的Timeline信息保存到timeline_01.json文件中,在Chrome浏览器的地址栏中输入chrome://tracing,然后load该文件,可以看到图像化的Profiling结果。
业务模型的Timeline如图所示:
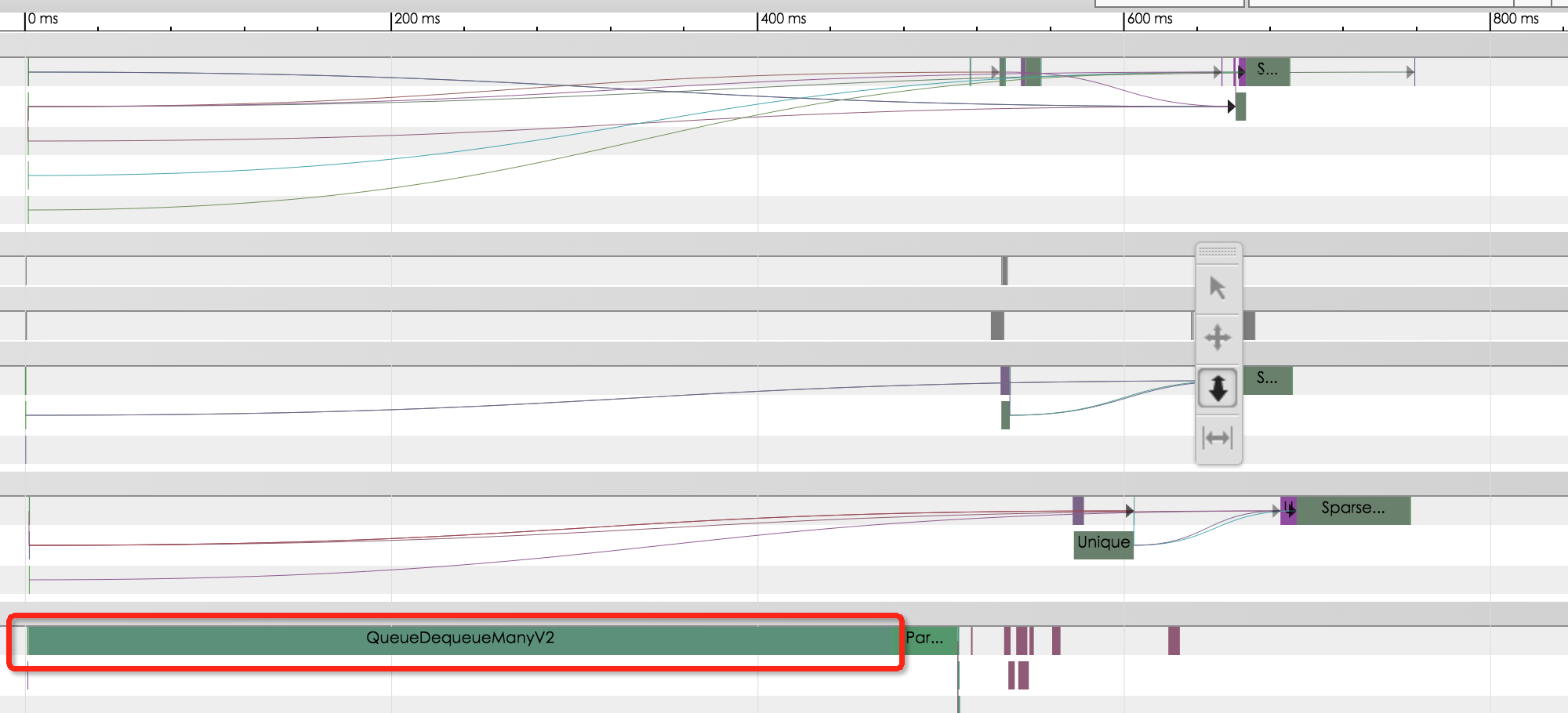
可以看到QueueDequeueManyV2这个OP耗时最久,约占整体时延的60%以上。通过分析TensorFlow源码,我们判断有两方面的原因:
- (1)Reader线程是Python线程,受制于Python的全局解释锁(GIL),Reader线程在训练时没有获得足够的调度执行;
- (2)Reader默认的接口函数TFRecordReader.read函数每次只读入一条数据,如果Batch Size比较大,读入一个Batch的数据需要频繁调用该接口,系统开销很大;
针对第一个问题,解决办法是使用TensorFlow Dataset接口,该接口不再使用Python线程读数据,而是用C++线程实现,避免了Python GIL问题。 针对第二个问题,社区提供了批量读数据接口TFRecordReader.read_up_to,能够指定每次读数据的数量。我们设置每次读入1000条数据,使读数句接口被调用的频次从10000次降低到10次,每轮训练时延降低2-3倍。
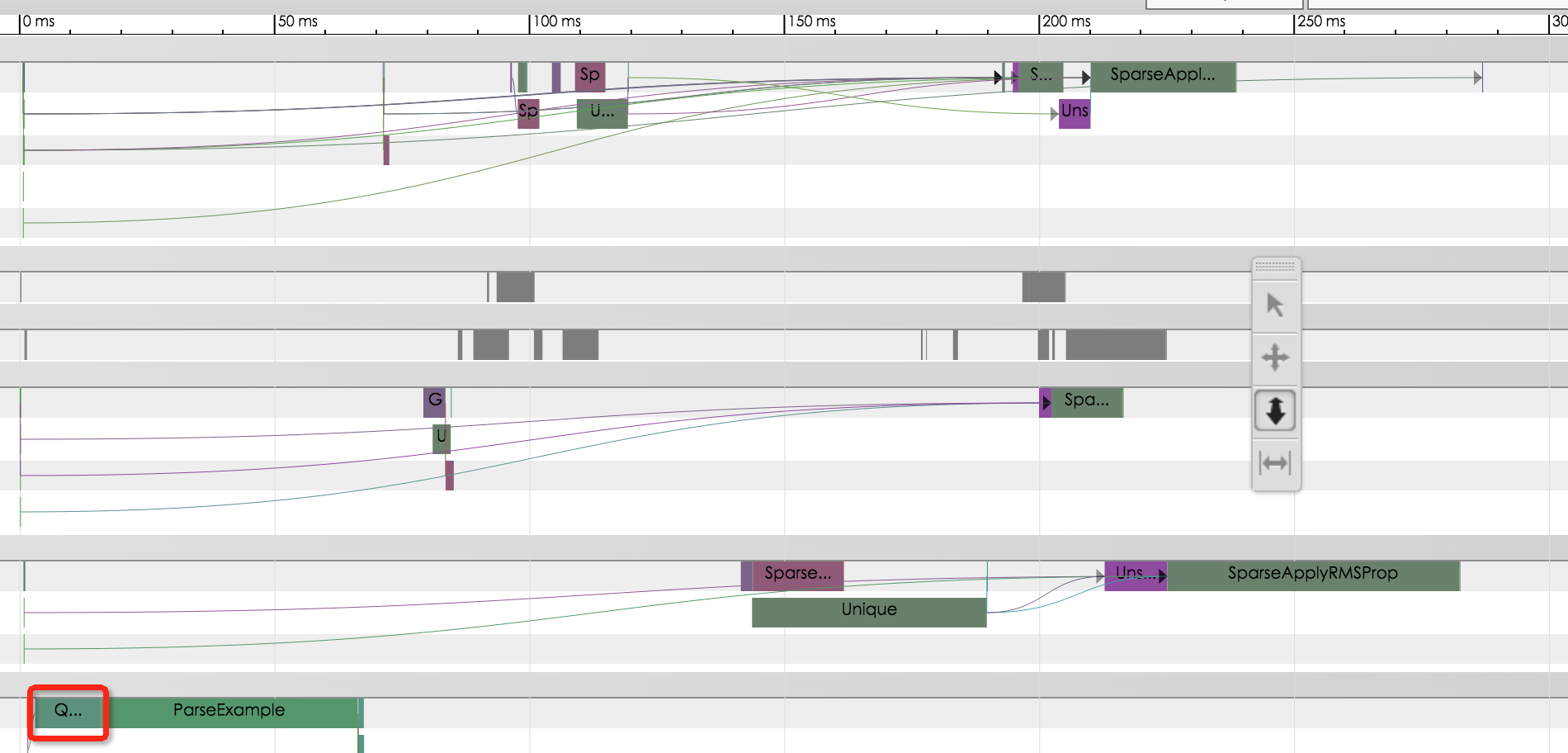
可以看到经过调优后,QueueDequeueManyV2耗时只有十几毫秒,每轮训练时延从原来的800多毫秒降低至不到300毫秒。
集群网络瓶颈
虽然使用了Mellanox的25G网卡,但是在WDL训练过程中,我们观察到Worker上的上行和下行网络流量抖动剧烈,幅度2-10Gbps,这是由于打满了PS网络带宽导致丢包。因为分布式训练参数都是保存和更新都是在PS上的,参数过多,加之模型网络较浅,计算很快,很容易形成多个Worker打一个PS的情况,导致PS的网络接口带宽被打满。
在推荐业务的WDL模型中,embedding张量的参数规模是千万级,TensorFlow的tf.embedding_lookup_sparse接口包含了几个OP,默认是分别摆放在PS和Worker上的。如图所示,颜色代表设备,embedding lookup需要在不同设备之前传输整个embedding变量,这意味着每轮Embedding的迭代更新需要将海量的参数在PS和Worker之间来回传输。
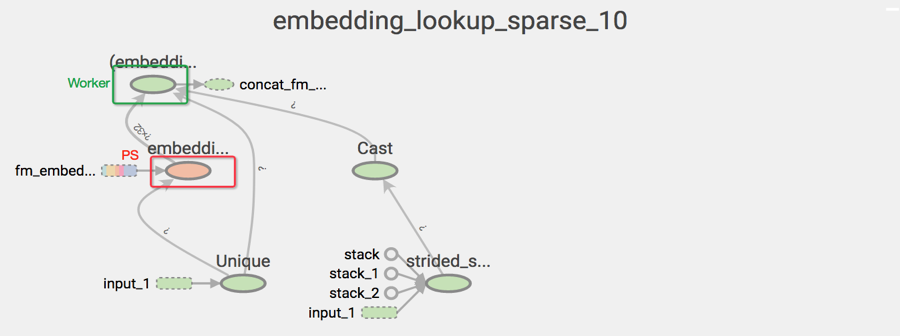
有效降低网络流量的方法是尽量让参数更新在一个设备上完成,即
with tf.device(PS):
do embedding computing
社区提供了一个接口方法正是按照这个思想实现的:embedding_lookup_sparse_with_distributed_aggregation接口,该接口可以将embedding计算的所使用的OP都放在变量所在的PS上,计算后转成稠密张量再传送到Worker上继续网络模型的计算。
从下图可以看到,embedding计算所涉及的OP都是在PS上,测试Worker的上行和下行网络流量也稳定在2-3Gpbs这一正常数值。

PS上的UniqueOP性能瓶颈
在使用分布式TensorFlow 跑广告推荐的WDL算法时,发现一个奇怪的现象:WDL算法在AFO上的性能只有手动分布式的1/4。手动分布式是指:不依赖YARN调度,用命令行方式在集群上分别启动PS和Worker作业。
使用Perf诊断PS进程热点,发现PS多线程在竞争一个内核自旋锁,PS整体上有30%-50%的CPU时间耗在malloc的在内核的spin_lock上。
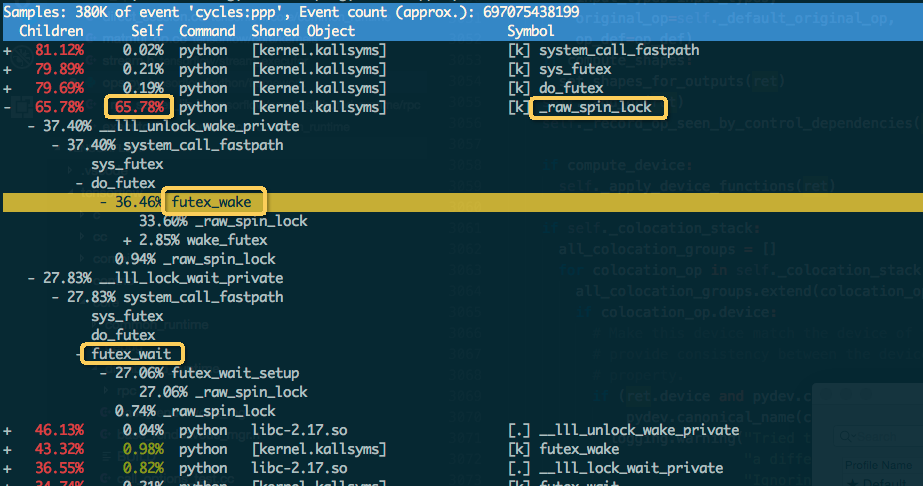
进一步查看PS进程栈,发现竞争内核自旋锁来自于malloc相关的系统调用。WDL的embedding_lookup_sparse会使用UniqueOp算子,TensorFlow支持OP多线程,UniqueOp计算时会开多线程,线程执行时会调用glibc的malloc申请内存。
经测试排查,发现Hadoop有一项默认的环境变量配置:
export MALLOC_ARENA_MAX="4"
该配置意思是限制进程所能使用的glibc内存池个数为4个。这意味着当进程开启多线程调用malloc时,最多从4个内存池中竞争申请,这限制了调用malloc的线程并行执行数量最多为4个。
翻查Hadoop社区相关讨论,当初增加这一配置的主要原因是:glibc的升级带来多线程ARENA的特性,可以提高malloc的并发性能,但同时也增加进程的虚拟内存(即top结果中的VIRT)。YARN管理进程树的虚拟内存和物理内存使用量,超过限制的进程树将被杀死。将MALLOC_ARENA_MAX的默认设置改为4之后,可以不至于VIRT增加很多,而且一般作业性能没有明显影响。
但这个默认配置对于WDL深度学习作业影响很大,我们去掉了这个环境配置,malloc并发性能极大提升。经过测试,WDL模型的平均训练时间性能减少至原来的1/4。
调优结果
注意:以下测试都去掉了Hadoop MALLOC_ARENA_MAX的默认配置
我们在AFO上针对业务的WDL模型做了性能调优前后的比对测试,测试环境参数如下:
模型:推荐广告模型WDL
OS:CentOS 7.1
CPU: Xeon E5 2.2G, 40 Cores
GPU:Nvidia P40
磁盘: Local Rotational Disk
网卡:Mellanox 25G(未使用RoCE)
TensorFlow版本:Release 1.4
CUDA/cuDNN: 8.0/5.1
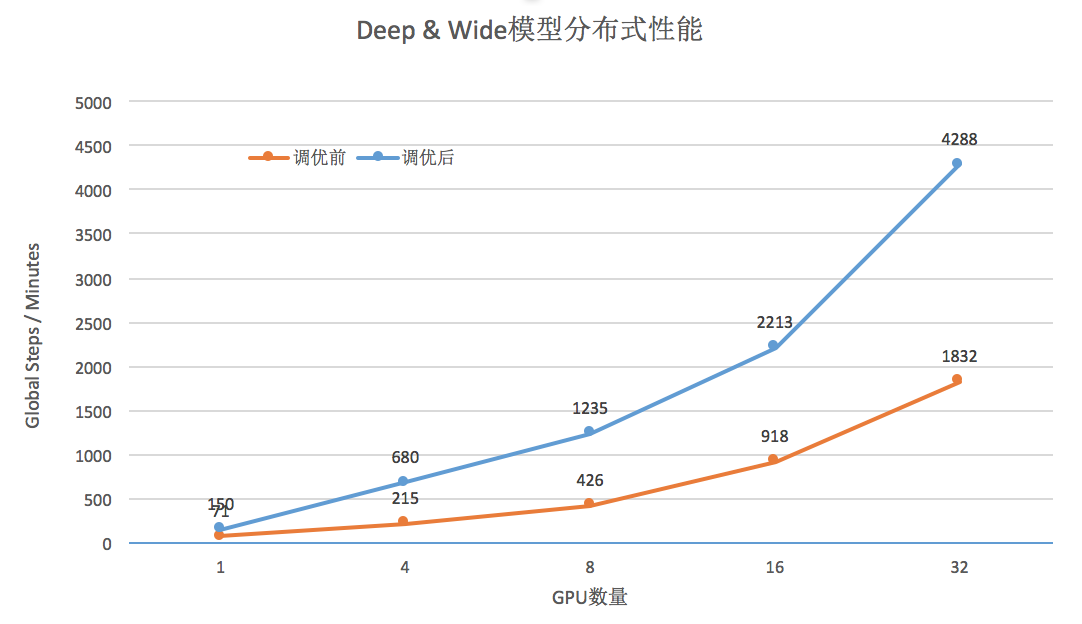
可以看到调优后,训练性能提高2-3倍,性能可以达到32个GPU线性加速。这意味着如果使用同样的资源,业务训练时间会更快,或者说在一定的性能要求下,资源节省更多。如果考虑优化MALLOC_ARENA_MAX的因素,调优后的训练性能提升约为10倍左右。
总结
我们使用TensorFlow训练WDL模型发现一些系统上的性能瓶颈点,通过针对性的调优不仅可以大大加速训练过程,而且可以提高GPU、带宽等资源的利用率。在深入挖掘系统热点瓶颈的过程中,我们也加深了对业务算法模型、TensorFlow框架的理解,具有技术储备的意义,有助于我们后续进一步优化深度学习平台性能,更好地为业务提供工程技术支持。
作者简介
- 郑坤,美团点评技术专家,2015年加入美团点评,负责深度学习平台、Docker平台的研发工作。
招聘
美团点评GPU计算团队,致力于打造公司一体化的深度学习基础设施平台,涉及到的技术包括:资源调度、高性能存储、高性能网络、深度学习框架等。目前平台还在建设中期,不论在系统底层、分布式架构、算法工程优化上都有很大的挑战!诚邀对这个领域感兴趣的同学加盟,不论是工程背景,还是算法背景我们都非常欢迎。有兴趣的同学可以发送简历到zhengkun@meituan.com。
