

美团广告实时索引的设计与实现
背景
在线广告是互联网行业常见的商业变现方式。从工程角度看,广告索引的结构和实现方式直接决定了整个系统的服务性能。本文以美团的搜索广告系统为蓝本,与读者一起探讨广告系统的工程奥秘。
领域问题
广告索引需具备以下基本特性:
- 层次化的索引结构。
- 实时化的索引更新。
层次投放模型
一般地,广告系统可抽象为如下投放模型,并实现检索、过滤等处理逻辑。
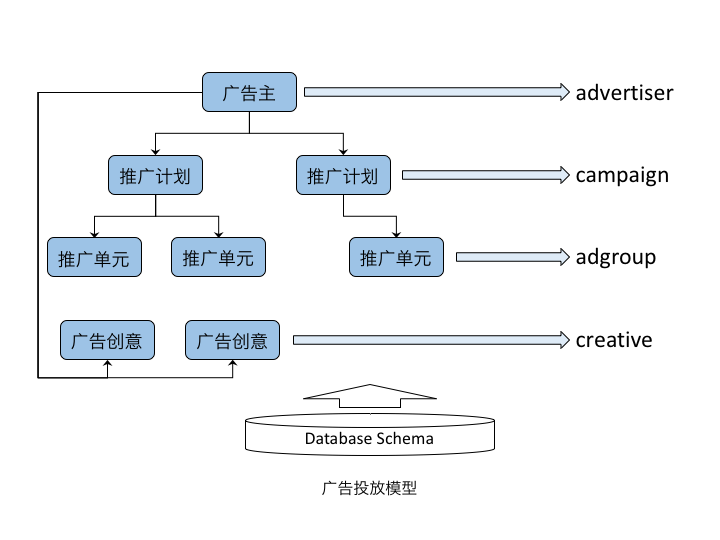
该层次结构的上下层之间是一对多的关系。一个广告主通常创建若干个推广计划,每个计划对应一个较长周期的KPI,比如一个月的预算和投放地域。一个推广计划中的多个推广单元分别用于更精细的投放控制,比如一次点击的最高出价、每日预算、定向条件等。广告创意是广告曝光使用的素材,根据业务特点,它可以从属于广告主或推广计划层级。
实时更新机制
层次结构可以更准确、更及时地反应广告主的投放控制需求。投放模型的每一层都会定义若干字段,用于实现各类投放控制。广告系统的大部分字段需要支持实时更新,比如审核状态、预算上下线状态等。例如,当一个推广单元由可投放状态变为暂停状态时,若该变更没有在索引中及时生效,就会造成大量的无效投放。
业界调研
目前,生产化的开源索引系统大部分为通用搜索引擎设计,基本无法同时满足上述条件。
- Apache Lucene
- 全文检索、支持动态脚本;实现为一个Library。
- 支持实时索引,但不支持层次结构。
- Sphinx
- 全文检索;实现为一个完整的Binary,二次开发难度大。
- 支持实时索引,但不支持层次结构。
因此,广告业界要么基于开源方案进行定制,要么从头开发自己的闭源系统。在经过再三考虑成本收益后,我们决定自行设计广告系统的索引系统。
索引设计
工程实践重点关注稳定性、扩展性、高性能等指标。
设计分解
设计阶段可分解为以下子需求。
实时索引
广告场景的更新流,涉及索引字段和各类属性的实时更新。特别是与上下线状态相关的属性字段,需要在若干毫秒内完成更新,对实时性有较高要求。
用于召回条件的索引字段,其更新可以滞后一些,如在几秒钟之内完成更新。采用分而治之的策略,可极大降低系统复杂度。
- 属性字段的更新:直接修改正排表的字段值,可以保证毫秒级完成。
- 索引字段的更新:涉及更新流实时计算、倒排索引等的处理过程,只需保证秒级完成。
此外,通过定期切换全量索引并追加增量索引,由索引快照确保数据的正确性。
层次结构
投放模型的主要实体是广告主(Advertiser)、推广计划(Campaign)、广告组(Adgroup)、创意(Creative)等。其中:
- 广告主和推广计划:定义用于控制广告投放的各类状态字段。
- 广告组:描述广告相关属性,例如竞价关键词、最高出价等。
- 创意:与广告的呈现、点击等相关的字段,如标题、创意地址、点击地址等。
一般地,广告检索、排序等均基于广告组粒度,广告的倒排索引也是建立在广告组层面。借鉴关系数据库的概念,可以把广告组作为正排主表(即一个Adgroup是一个doc),并对其建立倒排索引;把广告主、推广计划等作为辅表。主表与辅表之间通过外键关联。
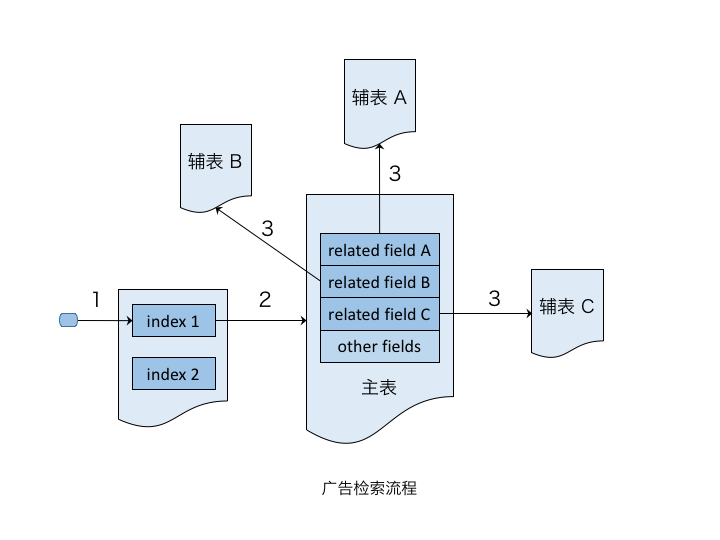
- 通过查询条件,从倒排索引中查找相关docID列表。
- 对每个docID,可从主表获取相关字段信息。
- 使用外键字段,分别获取对应辅表的字段信息。
检索流程中实现对各类字段值的同步过滤。
可靠高效
广告索引结构相对稳定且与具体业务场景耦合较弱,为避免Java虚拟机由于动态内存管理和垃圾回收机制带来的性能抖动,最终采用C++11作为开发语言。虽然Java可使用堆外内存,但是堆外堆内的数据拷贝对高并发访问仍是较大开销。项目严格遵循《Google C++ Style》,大幅降低了编程门槛。
在“读多写少”的业务场景,需要优先保证“读”的性能。检索是内存查找过程,属于计算密集型服务,为保证CPU的高并发,一般设计为无锁结构。可采用“一写多读”和延迟删除等技术,确保系统高效稳定运转。此外,巧妙利用数组结构,也进一步优化了读取性能。
灵活扩展
正排表、主辅表间的关系等是相对稳定的,而表内的字段类型需要支持扩展,比如用户自定义数据类型。甚至,倒排表类型也需要支持扩展,例如地理位置索引、关键词索引、携带负载信息的倒排索引等。通过继承接口,实现更多的定制化功能。
逻辑结构
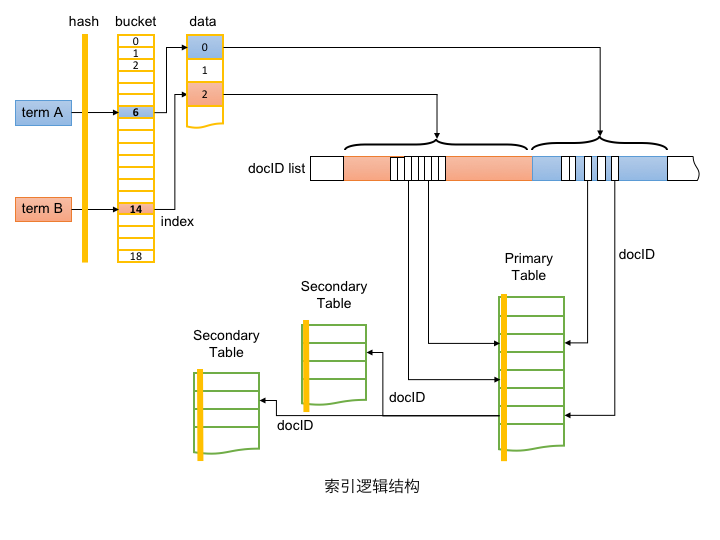
从功能角度,索引由Table和Index两部分组成。如上图所示,Index实现由Term到主表docID的转换;Table实现正排数据的存储,并通过docID实现主表与辅表的关联。
分层架构
索引库分为三层:
- 接口层:以API方式对外提供索引的构建、更新、检索、过滤等功能。
- 能力层:实现基于倒排表和正排表的索引功能,是系统的核心。
- 存储层:索引数据的内存布局和到文件的持久化存储。
索引实现
本节将自底向上,从存储层开始,逐一描述各层的设计细节和挑战点。
存储层
存储层负责内存分配以及数据的持久化,可使用mmap实现到虚拟内存空间的映射,由操作系统实现内存与文件的同步。此外,mmap也便于外部工具访问或校验数据的正确性。
将存储层抽象为分配器(Allocator)。针对不同的内存使用场景,如对内存连续性的要求、内存是否需要回收等,可定制实现不同的分配器。
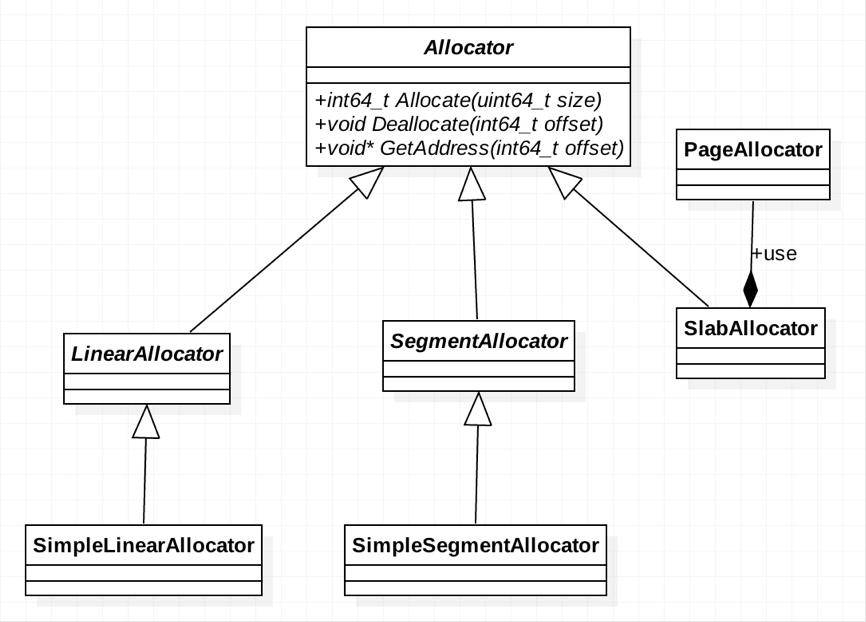
以下均为基于mmap的各类分配器,这里的“内存”是指调用进程的虚拟地址空间。实际的代码逻辑还涉及复杂的Metadata管理,下文并未提及。
简单的分配策略
LinearAllocator
分配连续地址空间的内存,即一整块大内存;当空间需要扩展时,会采用新的mmap文件映射,并延迟卸载旧的文件映射。
新映射会导致页表重新装载,大块内存映射会导致由物理内存装载带来的性能抖动。
一般用于空间需求相对固定的场景,如HashMap的bucket数组。
SegmentAllocator
为解决LinearAllocator在扩展时的性能抖动问题,可将内存区分段存储,即每次扩展只涉及一段,保证性能稳定。
分段导致内存空间不连续,但一般应用场景,如倒排索引的存储,很适合此法。
默认的段大小为64MB。
集约的分配策略
频繁的增加、删除、修改等数据操作将导致大量的外部碎片。采用压缩操作,可以使占用的内存更紧凑,但带来的对象移动成本却很难在性能和复杂度之间找到平衡点。在工程实践中,借鉴Linux物理内存的分配策略,自主实现了更适于业务场景的多个分配器。
- PageAllocator
- 页的大小为4KB,使用伙伴系统(Buddy System)的思想实现页的分配和回收。
- 页的分配基于SegmentAllocator,即先分段再分页。
在此简要阐述伙伴分配器的处理过程,为有效管理空闲块,每一级order持有一个空闲块的FreeList。设定最大级别order=4,即从order=0开始,由低到高,每级order块内页数分别为1、2、4、8、16等。分配时先找满足条件的最小块;若找不到则在上一级查找更大的块,并将该块分为两个“伙伴”,其中一个分配使用,另一个置于低一级的FreeList。
下图呈现了分配一个页大小的内存块前后的状态变化,分配前,分配器由order=0开始查找FreeList,直到order=4才找到空闲块。
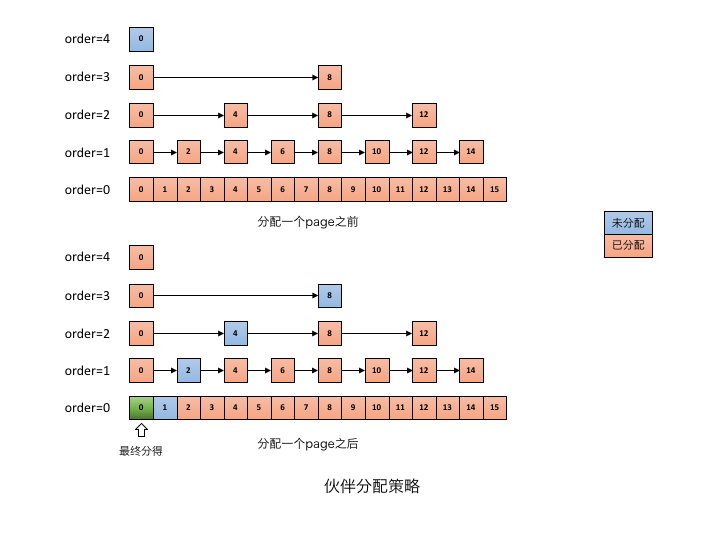
将该空闲块分为页数为8的2个伙伴,使用前一半,并将后一半挂载到order=3的FreeList;逐级重复此过程,直到返回所需的内存块,并将页数为1的空闲块挂在到order=0的FreeList。
当块释放时,会及时查看其伙伴是否空闲,并尽可能将两个空闲伙伴合并为更大的空闲块。这是分配过程的逆过程,不再赘述。
虽然PageAllocator有效地避免了外部碎片,却无法解决内部碎片的问题。为解决这类小对象的分配问题,实现了对象缓存分配器(SlabAllocator)。
- SlabAllocator
- 基于PageAllocator分配对象缓存,slab大小以页为单位。
- 空闲对象按内存大小定义为多个SlabManager,每个SlabManager持有一个PartialFreeList,用于放置含有空闲对象的slab。
对象的内存分配过程,即从对应的PartialFreeList获取含有空闲对象的slab,并从该slab分配对象。反之,释放过程为分配的逆过程。
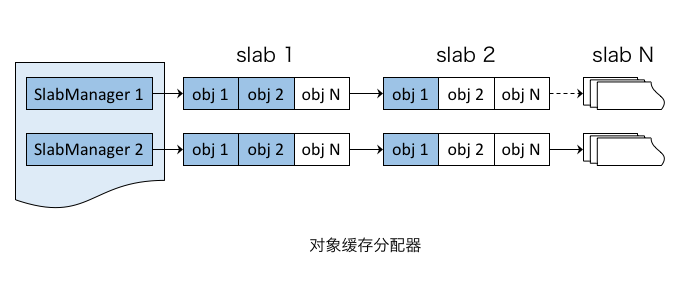
综上,实时索引存储结合了PageAllocator和SlabAllocator,有效地解决了内存管理的外部碎片和内部碎片问题,可确保系统高效稳定地长期运行。
能力层
能力层实现了正排表、倒排表等基础的存储能力,并支持索引能力的灵活扩展。
正向索引
也称为正排索引(Forward Index),即通过主键(Key)检索到文档(Doc)内容,以下简称正排表或Table。不同于搜索引擎的正排表数据结构,Table也可以单独用于NoSQL场景,类似于Kyoto Cabinet的哈希表。
Table不仅提供按主键的增加、删除、修改、查询等操作,也配合倒排表实现检索、过滤、读取等功能。作为核心数据结构,Table必须支持频繁的字段读取和各类型的正排过滤,需要高效和紧凑的实现。
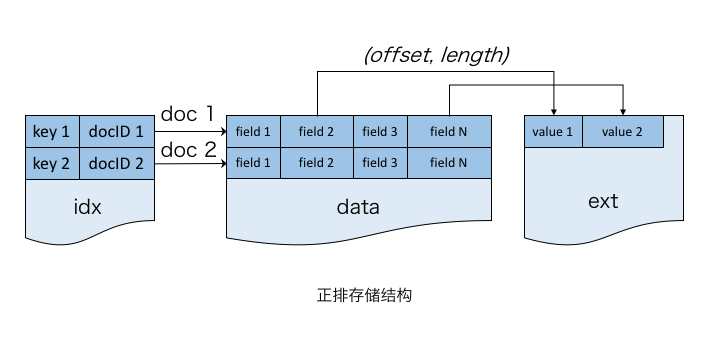
为支持按docID的随机访问,把Table设计为一个大数组结构(data区)。每个doc是数组的一个元素且长度固定。变长字段存储在扩展区(ext区),仅在doc中存储其在扩展区的偏移量和长度。与大部分搜索引擎的列存储不同,将data区按行存储,这样可针对业务场景,尽可能利用CPU与内存之间的缓存来提高访问效率。
此外,针对NoSQL场景,可通过HashMap实现主键到docID的映射(idx文件),这样就可支持主键到文档的随机访问。由于倒排索引的docID列表可以直接访问正排表,因此倒排检索并不会使用该idx。
反向索引
也称作倒排索引(Inverted Index),即通过关键词(Keyword)检索到文档内容。为支持复杂的业务场景,如遍历索引表时的算法粗排逻辑,在此抽象了索引器接口Indexer。

具体的Indexer仅需实现各接口方法,并将该类型注册到IndexerFactory,可通过工厂的NewIndexer方法获取Indexer实例,类图如下:
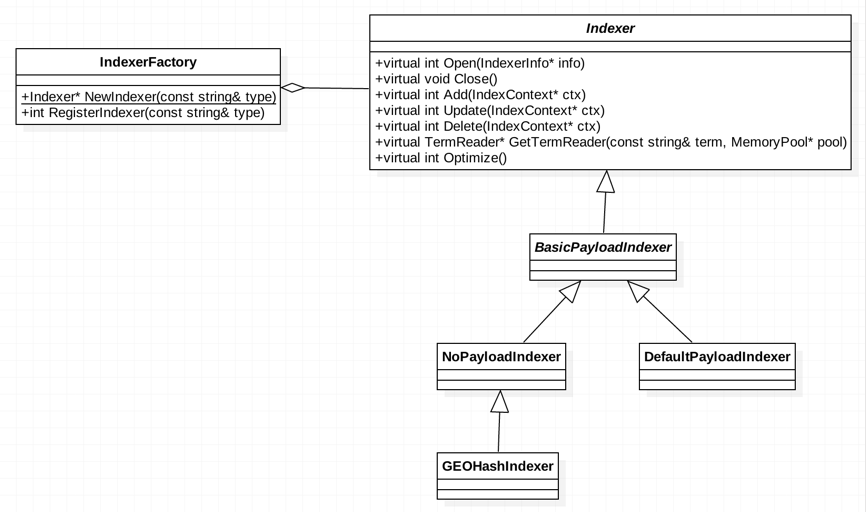
当前实现了三种常用的索引器:
- NoPayloadIndexer:最简单的倒排索引,倒排表为单纯的docID列表。
- DefaultPayloadIndexer:除docID外,倒排表还存储keyword在每个doc的负载信息。针对业务场景,可存储POI在每个Node粒度的静态质量分或最高出价。这样在访问正排表之前,就可完成一定的倒排优选过滤。
- GEOHashIndexer:即基于地理位置的Hash索引。
上述索引器的设计思路类似,仅阐述其共性的两个特征:
- 词典文件term:存储关键词、签名哈希、posting文件的偏移量和长度等。与Lucene采用的前缀压缩的树结构不同,在此实现为哈希表,虽然空间有所浪费,但可保证稳定的访问性能。
- 倒排表文件posting:存储docID列表、Payload等信息。检索操作是顺序扫描倒排列表,并在扫描过程中做一些基于Payload的过滤或倒排链间的布尔运算,如何充分利用高速缓存实现高性能的索引读取是设计和实现需要考虑的重要因素。在此基于segmentAllocator实现分段的内存分配,达到了效率和复杂度之间的微妙平衡。
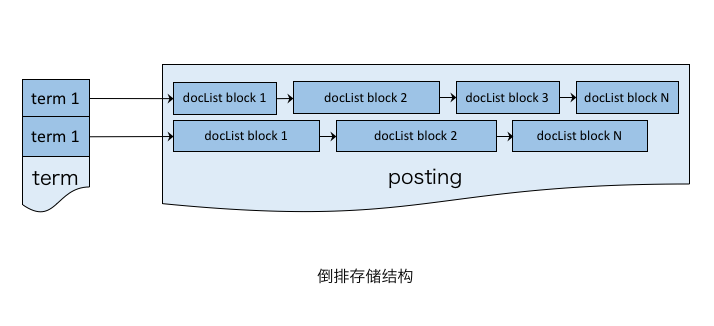
出于业务考虑,没有采用Lucene的Skip list结构,因为广告场景的doc数量没有搜索引擎多,且通常为单个倒排列表的操作。此外,若后续doc数量增长过快且索引变更频繁,可考虑对倒排列表的元素构建B+树结构,实现倒排元素的快速定位和修改。
接口层
接口层通过API与外界交互,并屏蔽内部的处理细节,其核心功能是提供检索和更新服务。
配置文件
配置文件用于描述整套索引的Schema,包括Metadata、Table、Index的定义,格式和内容如下:

可见,Index是构建在Table中的,但不是必选项;Table中各个字段的定义是Schema的核心。当Schema变化时,如增加字段、增加索引等,需要重新构建索引。篇幅有限,此处不展开定义的细节。
检索接口
检索由查找和过滤组成,前者产出查找到的docID集合,后者逐个对doc做各类基础过滤和业务过滤。

- Search:返回正排过滤后的ResultSet,内部组合了对DoSearch和DoFilter的调用。
- DoSearch:查询doc,返回原始的ResultSet,但并未对结果进行正排过滤。
- DoFilter:对DoSearch返回的ResultSet做正排过滤。
一般仅需调用Search就可实现全部功能;DoSearch和DoFilter可用于实现更复杂的业务逻辑。
以下为检索的语法描述:
/{table}/{indexer|keyfield}?query=xxxxxx&filter=xxxxx
第一部分为路径,用于指定表和索引。第二部分为参数,多个参数由&分隔,与URI参数格式一致,支持query、filter、Payload_filter、index_filter等。
由query参数定义对倒排索引的检索规则。目前仅支持单类型索引的检索,可通过index_filter实现组合索引的检索。可支持AND、OR、NOT等布尔运算,如下所示:
query=(A&B|C|D)!E
查询语法树基于Bison生成代码。针对业务场景常用的多个term求docID并集操作,通过修改Bison文法规则,消除了用于存储相邻两个term的doc合并结果的临时存储,直接将前一个term的doc并入当前结果集。该优化极大地减少了临时对象开销。
由filter参数定义各类正排表字段值过滤,多个键值对由“;”分割,支持单值字段的关系运算和多值字段的集合运算。
由Payload_filter参数定义Payload索引的过滤,目前仅支持单值字段的关系运算,多个键值对由“;”分割。
详细的过滤语法如下:
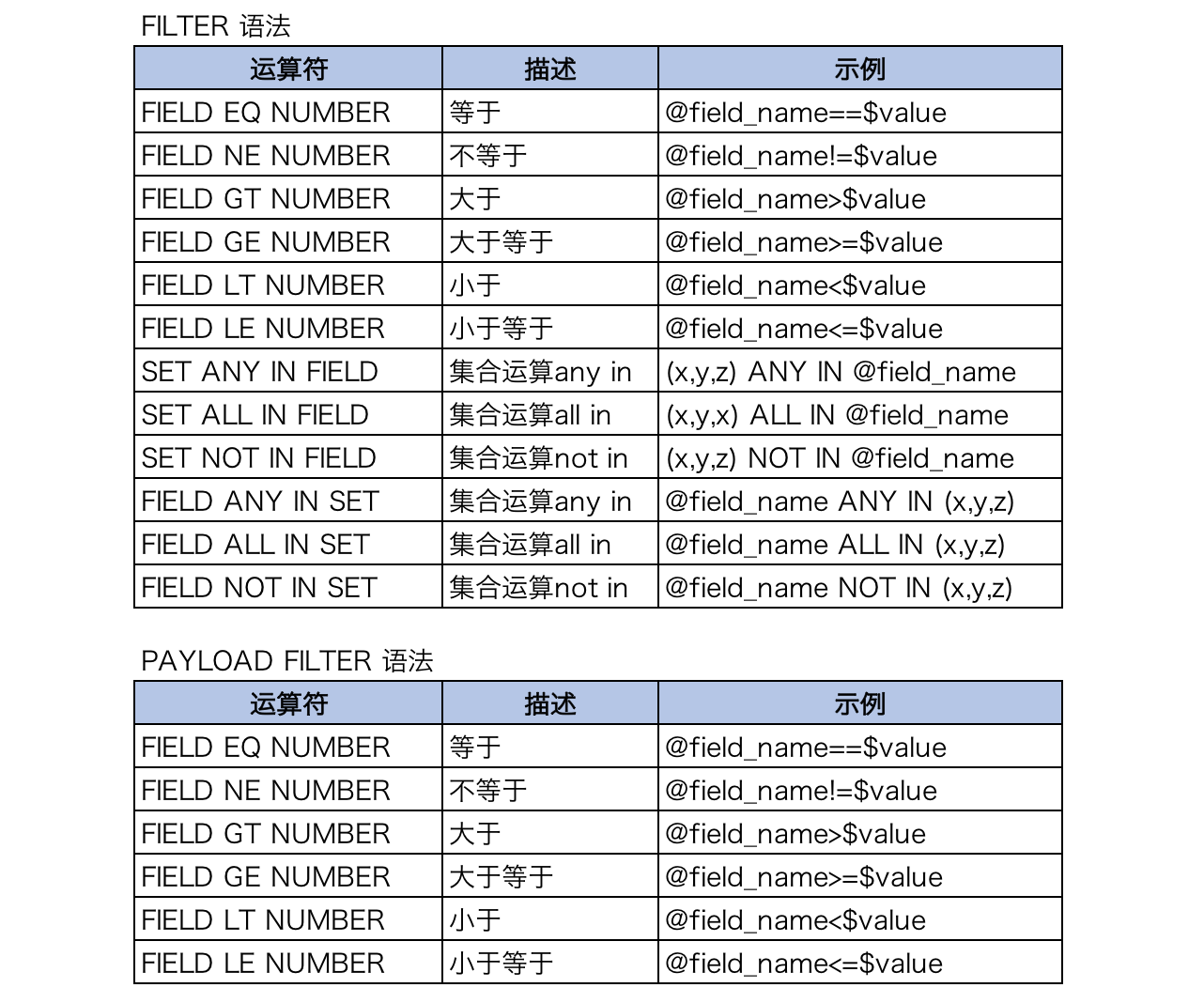
此外,由index_filter参数定义的索引过滤将直接操作倒排链。由于构造检索数据结构比正排过滤更复杂,此参数仅适用于召回的docList特别长但通过索引过滤的docList很短的场景。
结果集
结果集ResultSet的实现,参考了java.sql.ResultSet接口。通过cursor遍历结果集,采用inline函数频繁调用的开销。
实现为C++模板类,主要接口定义如下:

- Next:移动cursor到下一个doc,成功返回true,否则返回false。若已经是集合的最后一条记录,则返回false。
- GetValue:读取单值字段的值,字段类型由泛型参数T指定。如果获取失败返回默认值def_value。
- GetMultiValue:读取多值字段的值,返回指向值数组的指针,数组大小由size参数返回。读取失败返回null,size等于0。
更新接口
更新包括对doc的增加、修改、删除等操作。参数类型Document,表示一条doc记录,内容为待更新的doc的字段内容,key为字段名,value为对应的字段值。操作成功返回0,失败返回非0,可通过GetErrorString接口获取错误信息。

- 增加接口Add:将新的doc添加到Table和Index中。
- 修改接口Update:修改已存在的doc内容,涉及Table和Index的变更。
- 删除接口Delete:删除已存在的doc,涉及从Table和Index删除数据。
更新服务对接实时更新流,实现真正的广告实时索引。
更新系统
除以上描述的索引实现机制,生产系统还需要打通在线投放引擎与商家端、预算控制、反作弊等的更新流。
挑战与目标
数据更新系统的主要工作是将原始多个维度的信息进行聚合、平铺、计算后,最终输出线上检索引擎需要的维度和内容。
业务场景导致上游触发可能极不规律。为避免更新流出现的抖动,必须对实时更新的吞吐量做优化,留出充足的性能余量来应对触发的尖峰。此外,更新系统涉及多对多的维度转换,保持计算、更新触发等逻辑的可维护性是系统面临的主要挑战。
吞吐设计
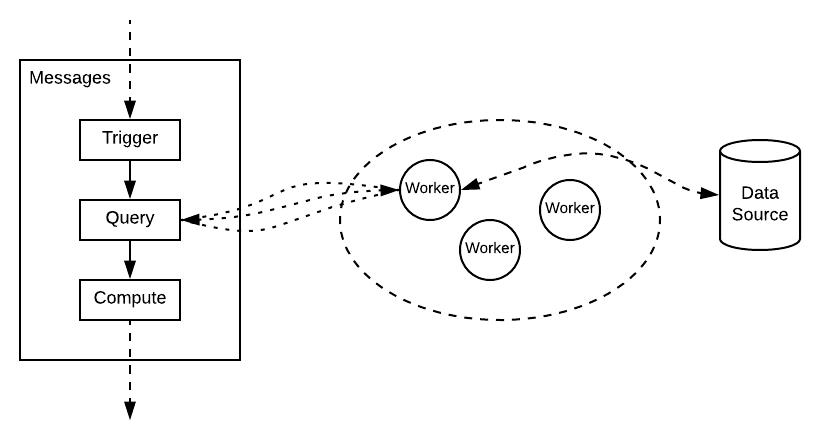
虽然更新系统需要大量的计算资源,但由于需要对几十种外部数据源进行查询,因此仍属于IO密集型应用。优化外部数据源访问机制,是吞吐量优化的主要目标。
在此,采取经典的批量化方法,即集群内部,对于可以批量查询的一类数据源,全部收拢到一类特定的worker上来处理。在短时间内,worker聚合数据源并逐次返回给各个需要数据的数据流。处理一种数据源的worker可以有多个,根据同类型的查询汇集到同一个worker批量查询后返回。在这个划分后,就可以做一系列的逻辑优化来提升吞吐量。
分层抽象
除生成商家端的投放模型数据,更新系统还需处理针对各种业务场景的过滤,以及广告呈现的各类专属信息。业务变更可能涉及多个数据源的逻辑调整,只有简洁清晰的分成抽象,才能应对业务迭代的复杂度。
工程实践中,将外部数据源抽象为统一的Schema,既做到了数据源对业务逻辑透明,也可借助编译器和类型系统来实现完整的校验,将更多问题提前到编译期解决。
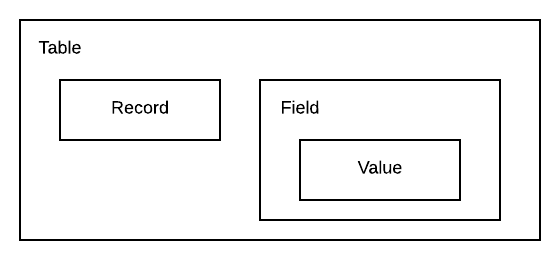
将数据定义为表(Table)、记录(Record)、字段(Field)、值(Value)等抽象类型,并将其定义为Scala Path Dependent Type,方便编译器对程序内部的逻辑进行校验。
可复用设计
多对多维度的计算场景中,每个字段的处理函数(DFP)应该尽可能地简单、可复用。例如,每个输出字段(DF)的DFP只描述需要的源数据字段(SF)和该字段计算逻辑,并不描述所需的SF(1)到SF(n)之间的查询或路由关系。
此外,DFP也不与最终输出的层级绑定。层级绑定在定义输出消息包含的字段时完成,即定义消息的时候需要定义这个消息的主键在哪一个层级上,同时绑定一系列的DFP到消息上。
这样,DFP只需单纯地描述字段内容的生成逻辑。如果业务场景需要将同一个DF平铺到不同层级,只要在该层级的输出消息上引用同一个DFP即可。
触发机制
更新系统需要接收数据源的状态变动,判断是否触发更新,并需要更新哪些索引字段、最终生成更新消息。
为实现数据源变动的自动触发机制,需要描述以下信息:
- 数据间的关联关系:实现描述关联关系的语法,即在描述外部数据源的同时就描述关联关系,后续字段查询时的路由将由框架处理。
- DFP依赖的SF信息:仅对单子段处理的简单DFP,可通过配置化方式,将依赖的SF固化在编译期;对多种数据源的复杂DFP,可通过源码分析来获取该DFP依赖的SF,无需用户维护依赖关系。
生产实践
早期的搜索广告是基于自然搜索的系统架构建的,随着业务的发展,需要根据广告特点进行系统改造。新的广告索引实现了纯粹的实时更新和层次化结构,已经在美团搜索广告上线。该架构也适用于各类非搜索的业务场景。
系统架构
作为整个系统的核心,基于实时索引构建的广告检索过滤服务(RS),承担了广告检索和各类业务过滤功能。日常的业务迭代,均可通过升级索引配置完成。
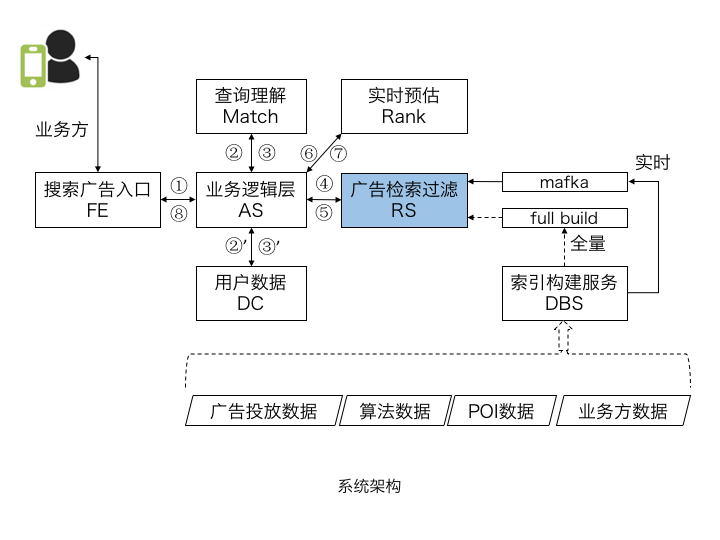
此外,为提升系统的吞吐量,多个模块已实现服务端异步化。
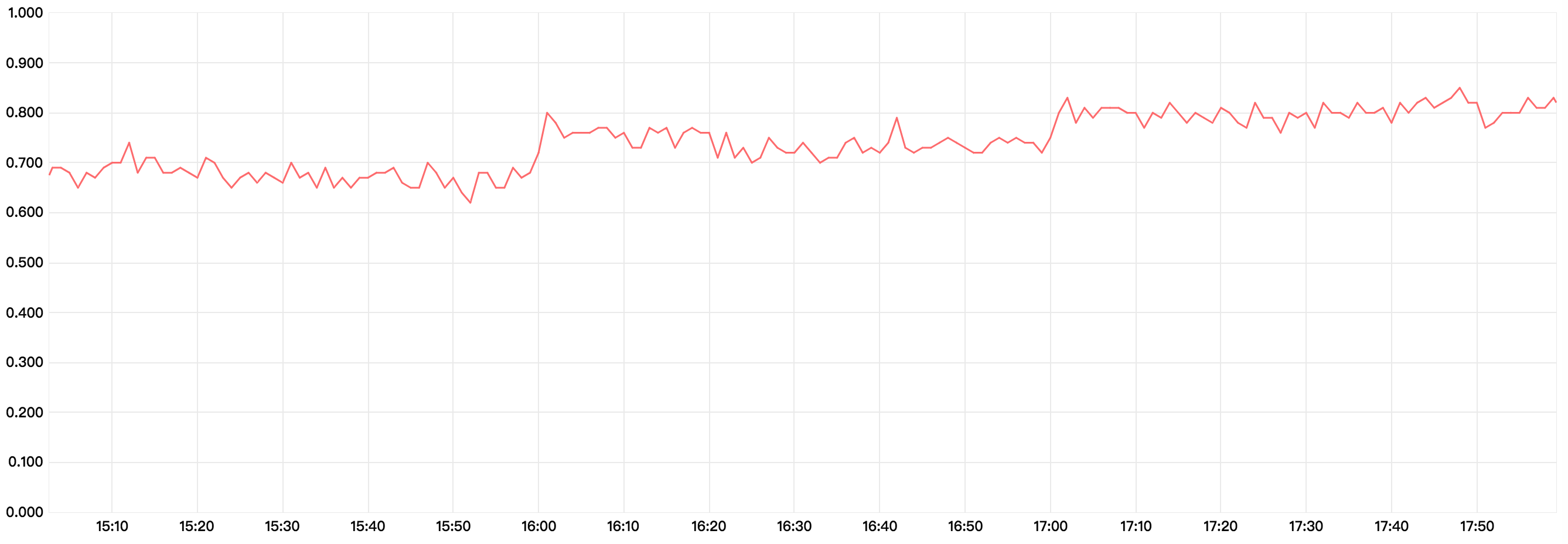
性能优化
以下为监控系统的性能曲线,索引中的doc数量为百万级别,时延的单位是毫秒。
后续规划
为便于实时索引与其他生产系统的结合,除进一步的性能优化和功能扩展外,我们还计划完成多项功能支持。
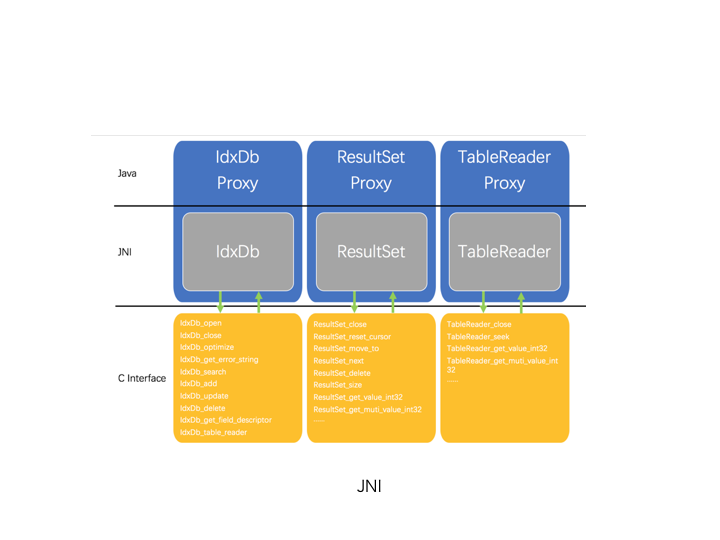
JNI
通过JNI,将Table作为单独的NoSQL,为Java提供本地缓存。如广告系统的实时预估模块,可使用Table存储模型使用的广告特征。
SQL
提供SQL语法,提供简单的SQL支持,进一步降低使用门槛。提供JDBC,进一步简化Java的调用。
参考资料
- Apache Lucene http://lucene.apache.org/
- Sphinx http://sphinxsearch.com/
- "Understanding the Linux Virtual Memory Manager" https://www.kernel.org/doc/gorman/html/understand/
- Kyoto Cabinet http://fallabs.com/kyotocabinet/
- GNU Bison https://www.gnu.org/software/bison/
作者简介
- 仓魁:广告平台搜索广告引擎组架构师,主导实时广告索引系统的设计与实现。擅长C++、Java等多种编程语言,对异步化系统、后台服务调优等有深入研究。
- 晓晖:广告平台搜索广告引擎组核心开发,负责实时更新流的设计与实现。在广告平台率先尝试Scala语言,并将其用于大规模工程实践。
- 刘铮:广告平台搜索广告引擎组负责人,具有多年互联网后台开发经验,曾领导多次系统重构。
- 蔡平:广告平台搜索广告引擎组点评侧负责人,全面负责点评侧系统的架构和优化。
招聘信息
有志于从事Linux后台开发,对计算广告、高性能计算、分布式系统等有兴趣的朋友,请通过邮箱与我们联系。联系邮箱:liuzheng04@meituan.com 。
