

深度学习在文本领域的应用
背景
近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点。而深度学习技术突飞猛进的发展离不开海量数据的积累、计算能力的提升和算法模型的改进。本文主要介绍深度学习技术在文本领域的应用,文本领域大致可分为4个维度:词、句子、篇章、系统级应用。
- 词。分词方面,从最经典的前后向匹配到条件随机场(Conditional Random Field,CRF)序列标注,到现在Bi-LSTM+CRF模型,已经不需要设计特征,从字粒度就能做到最好的序列标注效果,并且可以推广到文本中序列标注问题上,比如词性标注和专门识别等。
- 句子。Parser方面,除词粒度介绍的深度学习序列标注外,还可以使用深度学习模型改善Shift-Reduce中间分类判断效果;句子生成方面,可以通过序列到序列(Seq2Seq)模型训练自动的句子生成器,可用于闲聊或者句子改写等场景。
- 篇章。情感分析方面,可以使用卷积神经网络对输入文本直接建模预测情感标签;阅读理解方面,可以设计具有记忆功能的循环神经网络来做阅读理解,这个也是近年非常热的研究问题。
- 系统级应用。信息检索方面,把深度学习技术用在文本匹配做相似度计算,可以通过BOW、卷积神经网络或循环神经网络表示再学习匹配关系(如DSSM系列),还有使用DNN做排序模型(如Google的Wide & Deep等,后面会重点介绍);机器翻译方面,源于Seq2Seq模型到Stack-LSTM + Attention等多层LSTM网络,使得基于词的统计机器翻译模型已经被基于神经网络的翻译模型超越,并且已经应用到产品中,比如谷歌翻译、百度翻译、有道翻译等;智能交互方面,在做闲聊、对话、问答等系统时深度学习在分类、状态管理(如深度强化学习)、回复生成等环节都有很好的应用。
总之,上面这些文本领域的深度学习应用只是冰山一角,深度学习应用还有知识图谱、自动摘要、语音、图像文本生成等。总体趋势是,各文本研究和应用的方向都在尝试深度学习技术,并分别取得了进展。在文本领域,如果想跟图像、语音那样取得突破性进展还面临重重困难,如不同任务的大规模标注数据缺乏,如何建模能捕捉语言的逻辑性以及所蕴含的地域、文化特色等等。限于篇幅,本文只对美团在文本中应用较多的文本匹配、排序模型进行介绍。
基于深度学习的文本匹配
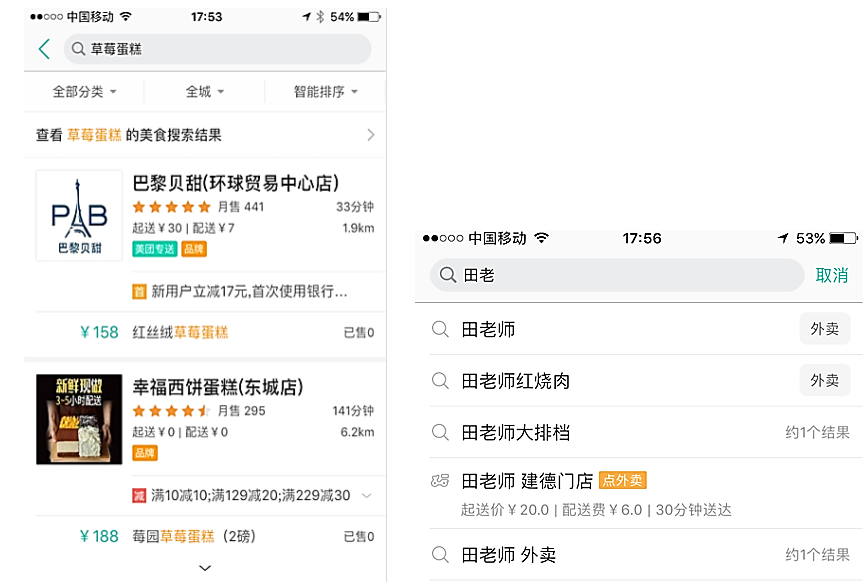
文本匹配在很多领域都有用到,尤其是信息检索相关场景,比如搜索的Query和Doc、广告中Query-Ad、搜索Suggestion中Query前缀和Query(见图1)、关键词推荐中Query和Query、文档去重时Doc和Doc等。
文本匹配主要研究计算两段文本的相似度问题。相似度问题包含两层:一是两段文本如何表示可使得计算机方便处理,这需要研究不同的表示方法效果的区别:二是如何定义相似度来作为优化目标,如语义匹配相似度、点击关系相似度、用户行为相似度等,这和业务场景关系很紧密。
在解决这两个问题过程中会遇到很多难题,其中一个难题就是设计模型如何充分考虑语义。因为中文的多义词、同义词非常普遍,它们在不同的语境中表达的含义是不一样的。比如苹果多少钱一台?苹果多少钱一斤?对于前者,根据“一台”能看出它是指苹果品牌的电子设备,后者则是指水果。当然,还有很多语言现象更加困难,比如语气、语境、口语的不同表述等。
文本的表示和匹配是本节的主线,如何做到语义层面匹配就成为本节的主旨。 受到整体技术的演进影响,文本的匹配技术同样有一个顺应时代的技术历程,如图2所示。

1. 向量空间
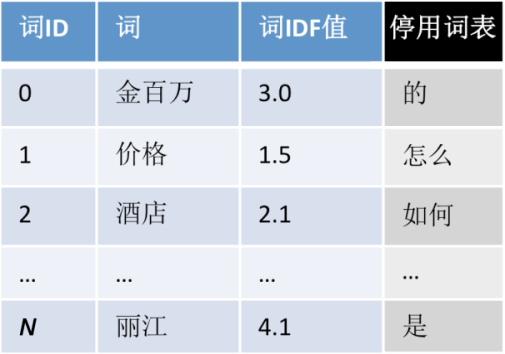
1970年左右提出的向量空间模型,就是把文档表示词表维度的向量通过TF-IDF计算出词的权重,比如一种标准词表包含词ID、词和IDF,另一种是停用词表,如图3所示。
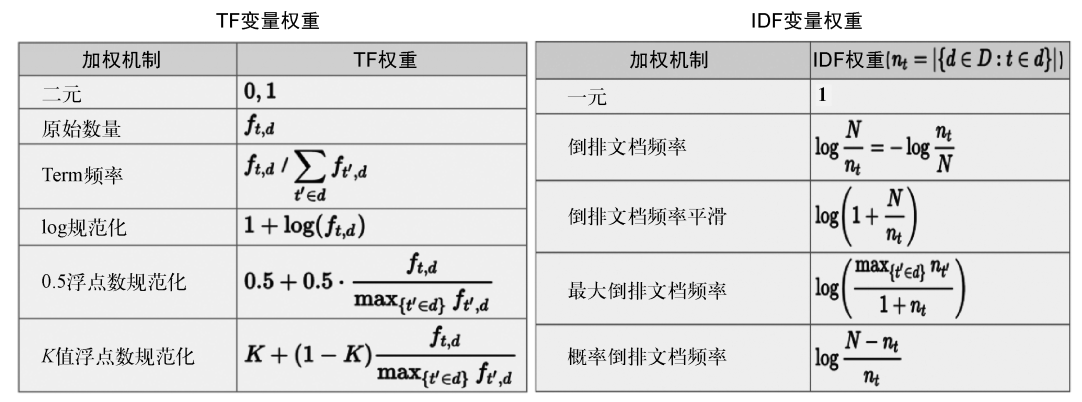
对文本“丽江的酒店价格”分词去除停用词后,得到丽江、酒店、价格,词出现次数是1,查表IDF得到这句文本的表示:[0, 1.5, 2.1, 0, 0, …, 0, 4.1]。其中权重使用的是TF×IDF,TF是Term在文本里的频次,IDF是逆文档频次,两者定义有很多形式,如图4所示。这里使用第二种定义。
向量空间模型用高维稀疏向量来表示文档,简单明了。对应维度使用TF-IDF计算,从信息论角度包含了词和文档的点互信息熵,以及文档的信息编码长度。文档有了向量表示,那么如何计算相似度?度量的公式有Jaccard、Cosine、Euclidean distance、BM25等,其中BM25是衡量文档匹配相似度非常经典的方法,公式如下:
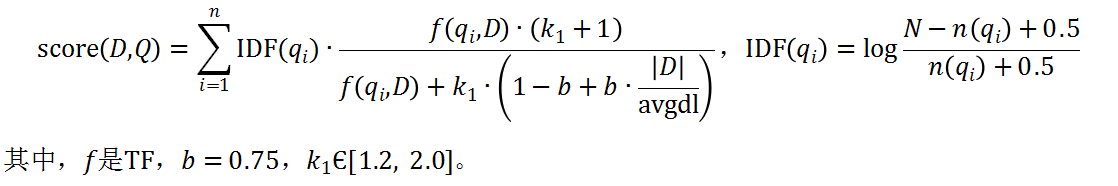
向量空间模型虽然不能包含同义词、多义词的信息,且维度随着词典增大变得很大,但因为它简单明了,效果不错,目前仍然是各检索系统必备的特征。
2. 矩阵分解
向量空间模型的高维度对语义信息刻画不好,文档集合会表示成高维稀疏大矩阵。1990年左右,有人研究通过矩阵分解的方法,把高维稀疏矩阵分解成两个狭长小矩阵,而这两个低维矩阵包含了语义信息,这个过程即潜在语义分析。
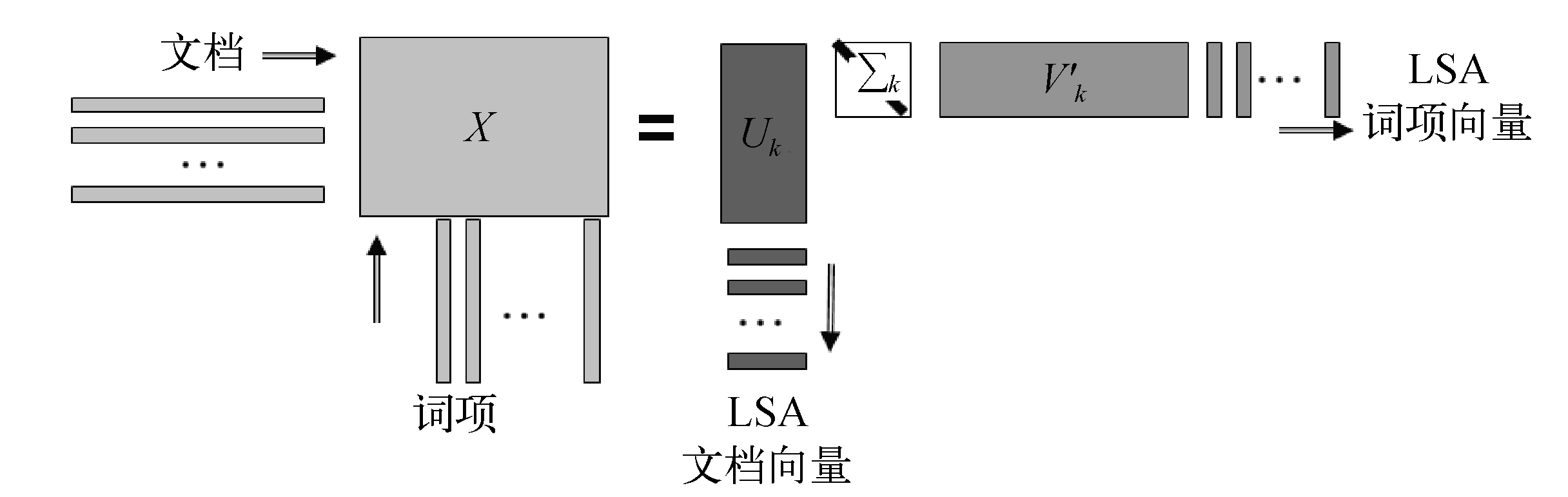
假设有N篇文档,共有V个词,用TF-IDF的向量空间表示一个N×V的稀疏矩阵X,词和文档的语义分析就在这个共现矩阵上操作。这个共现矩阵通过奇异值分解, 能变成三个矩阵,狭长矩阵U的维度是N×K,V的维度是K×V,中间是对角阵K×K维,如图5所示。
经过分解后,每个文档由K维向量表示,(K<<V),代表了潜在语义信息,可以看成是文档需要表达的语义空间表示。V矩阵代表词在潜空间上的分布都是通过共现矩阵分解得到的。
潜在语义分析能对文档或者词做低维度语义表示,在做匹配时其性能较高(比如文档有效词数大于K),它包含语义信息,对于语义相同的一些文档较准确。但是,潜在语义分析对多义词语义的建模不好,并且K维语义向量完全基于数学分解得到,物理含义不明确。因此,在2000年左右,为解决上述问题,主题模型出现了。
3. 主题模型
2000~2015年,以概率图模型为基础的主题模型掀起了一股热潮,那么究竟这种模型有什么吸引大家的优势呢?
pLSA(Probabilistic Latent Semantic Analysis)
pLSA在潜在语义分析之上引入了主题概念。它是一种语义含义,对文档的主题建模不再是矩阵分解,而是概率分布(比如多项式分布),这样就能解决多义词的分布问题,并且主题是有明确含义的。但这种分析的基础仍然是文档和词的共现频率,分析的目标是建立词/文档与这些潜在主题的关系,而这种潜在主题进而成为语义关联的一种桥梁。这种转变过渡可如图6所示。
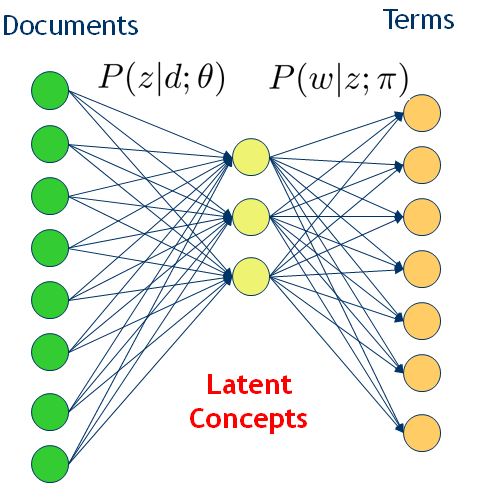
假设每篇文章都由若干主题构成,每个主题的概率是p(z|d),在给定主题的条件下,每个词都以一定的概率p(w|z)产生。这样,文档和词的共现可以用一种产生式的方式来描述:
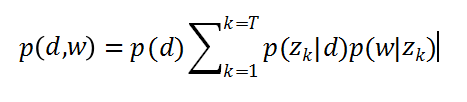
其概率图模型如图7所示:
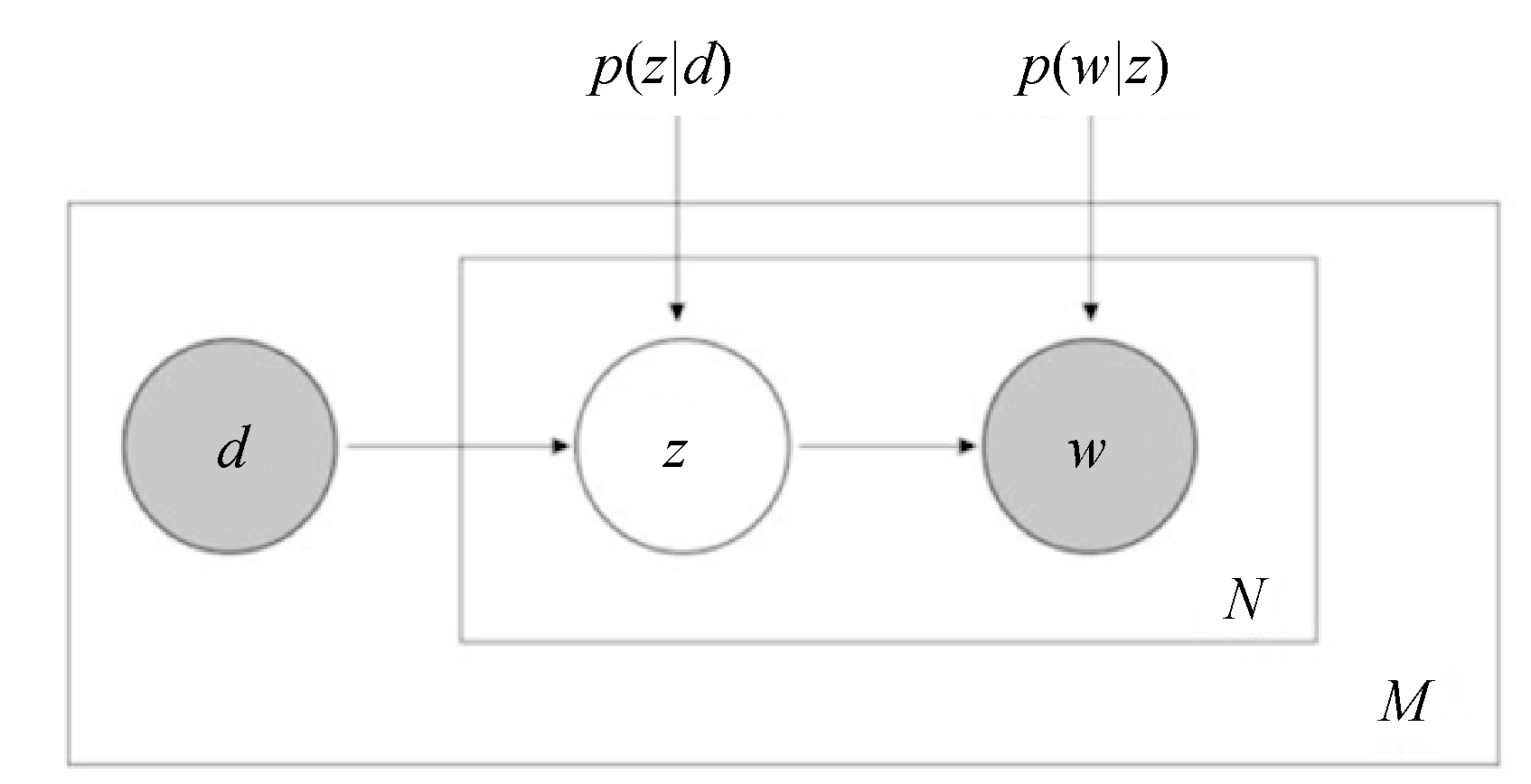
可以通过EM算法把p(z|d)和p(w|z)作为参数来学习,具体算法参考Thomas Hofmann的pLSA论文。需要学习的p(z|d)参数数目是主题数和文档数乘的关系,p(w|z)是词表数乘主题数的关系,参数空间很大,容易过拟合。因而我们引入多项式分布的共轭分布来做贝叶斯建模,即LDA使用的方法。
LDA(Latent Dirichlet Allocation)
如果说pLSA是频度学派代表,那LDA就是贝叶斯学派代表。LDA通过引入Dirichlet分布作为多项式共轭先验,在数学上完整解释了一个文档生成过程,其概率图模型如图8所示。
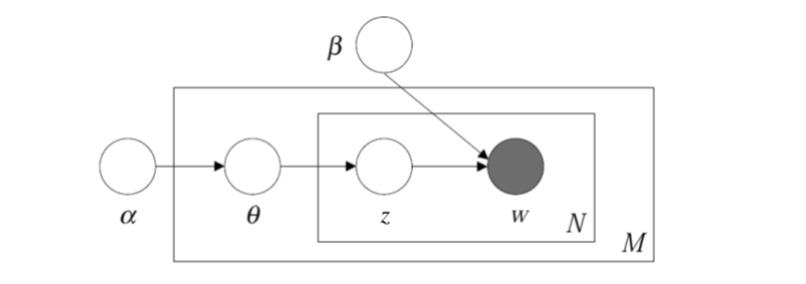
和pLSA概率图模型不太一样,LDA概率图模型引入了两个随机变量α和β,它们就是控制参数分布的分布,即文档-主题符合多项式分布。这个多项式分布的产生受Dirichlet先验分布控制,可以使用变分期望最大化(Variational EM)和吉布斯采样(Gibbs Sampling)来推导参数,这里不展开叙述。
总体来讲,主题模型引入了“Topic”这个有物理含义的概念,并且模型通过共现信息能学到同义、多义、语义相关等信息。得到的主题概率分布作为表示,变得更加合理有意义。有了文档的表示,在匹配时,我们不仅可以使用之前的度量方式,还可以引入KL等度量分布的公式,这在文本匹配领域应用很多。当然,主题模型会存在一些问题,比如对短文本推断效果不好、训练参数多速度慢、引入随机过程建模避免主题数目人工设定不合理问题等。随着研究进一步发展,这些问题基本都有较好解决,比如针对训练速度慢的问题,从LDA到SparseLDA、AliasLDA, 再到LightLDA、WarpLDA等,采样速度从O(K)降低O(1)到。
4. 深度学习
2013年,Tomas Mikolov发表了Word2Vec相关的论文,提出的两个模型CBOW(Continuous Bag of Words,连续词袋)和Skip-Gram能极快地训练出词嵌入,并且能对词向量加减运算,这得到了广泛关注。在这项工作之前,神经网络模型经历了很长的演进历程。这里先介绍2003年Yoshua Bengio使用神经网络做语言模型的工作,Word2Vec也是众多改进之一。
神经网络语言模型
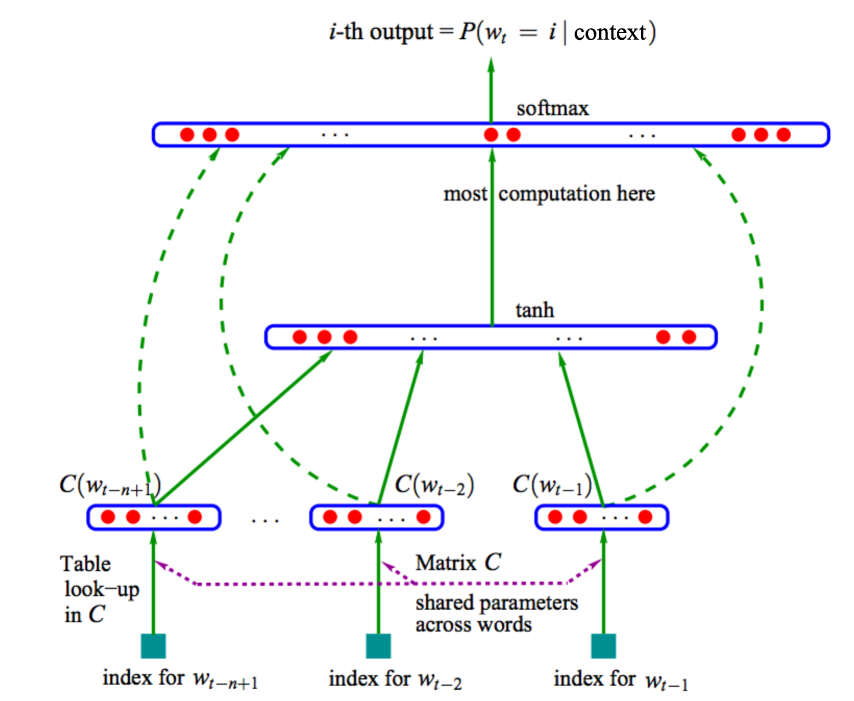
在2003年,Yoshua Bengio使用神经网络来训练语言模型比N-Gram的效果好很多,网络结构如图9所示。输入是N-Gram的词,预测下一个词。前n个词通过词向量矩阵Matrix C(维度:n*emb_size)查出该词的稠密向量C(w(t-1)),C(w(t-2));再分别连接到隐含层(Hidden Layer)做非线性变换;再和输出层连接做Softmax预测下一个词的概率;训练时根据最外层误差反向传播以调节网络权重。可以看出,该模型的训练复杂度为O(n×emb_size + n×emb_size×hidden_size + hidden_size×output_size),其中n为5~10,emb_size为64~1024,hidden_size为64~1023,output_size是词表大小,比如为10^7。因为Softmax在概率归一化时,需要所有词的值,所以复杂度主要体现在最后一层。从此以后,提出了很多优化算法,比如Hierarchical Softmax、噪声对比估计(Noise Contrastive Estimation)等。
Word2Vec
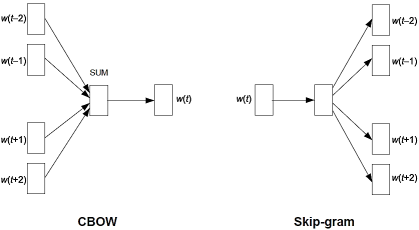
Word2Vec的网络结构有CBOW和Skip-Gram两种,如图10所示。相比NNLM,Word2Vec减少了隐含层,只有投影层。输出层是树状的Softmax,对每个词做哈夫曼编码,预测词时只需要对路径上的0、1编码做预测,从而复杂度从O(V)降低到O(log(V))。
以CBOW为例,算法流程如下:
(1) 上下文词(窗口大小是Win)的词向量对应维相加映射到投影层。 (2) 投影层经Sigmoid变换后预测当前词的编码路径(哈夫曼树)。 (3) 使用交叉熵损失函数(Cross Entropy Loss)反向传播,更新Embedding层参数和中间层参数。 (4) 训练使用反向传播机制,优化方法使用SGD。
从该算法流程可以看出,最外层的预测复杂度大幅降低,隐含层也去掉,这使得计算速度极大提高。该算法可得到词的Dense 的Word Embedding,这是一个非常好的表示,可以用来计算文本的匹配度。但由于该模型的学习目标是预测词发生概率,即语言模型,所以从海量语料中学习到的是词的通用语义信息,无法直接应用于定制业务的匹配场景。能否根据业务场景对语义表示和匹配同时建模,以提升匹配效果呢?DSSM系列工作就充分考虑了表示和匹配。
DSSM系列
这类方法可以把表示和学习融合起来建模,比较有代表性的是微软的相关工作。下面将介绍DSSM系列内容。
(1) DSSM模型框架
DSSM网络结构如图11所示:
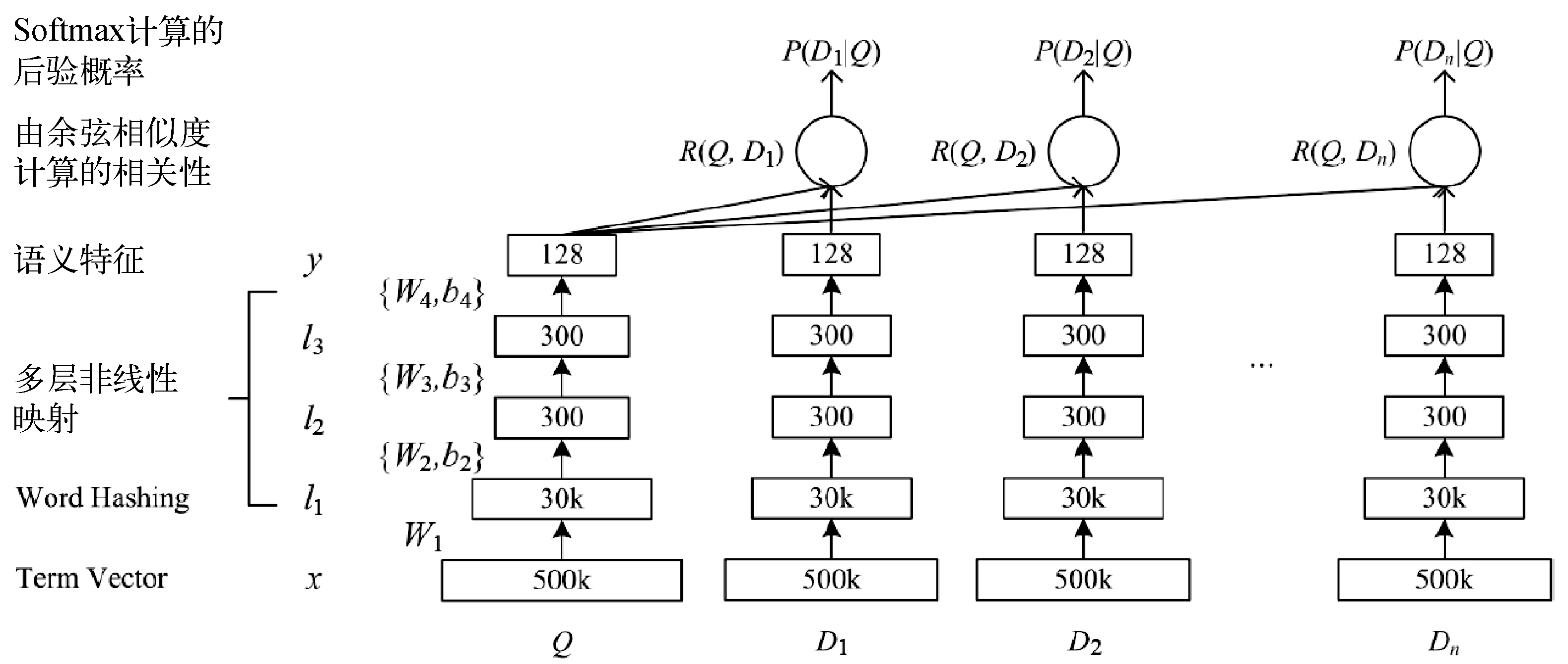
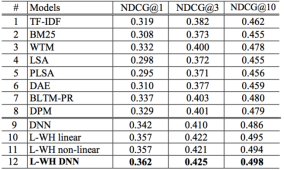
使用搜索的点击数据训练语义模型,输入查询Query(Q)和展现点击的Doc(D)列表,先对Q和D做语义表示,再通过Q-DK的Cosine计算相似度,通过Softmax来区分点击与否。其中,语义表示先使用词散列对词表做降维(比如英文字母的Ngram),经过几层全连接和非线性变化后得到128维的Q和D的表示。从实验结论可知,NDCG指标提升还是很明显的,如图12所示。
**(2) CLSM **
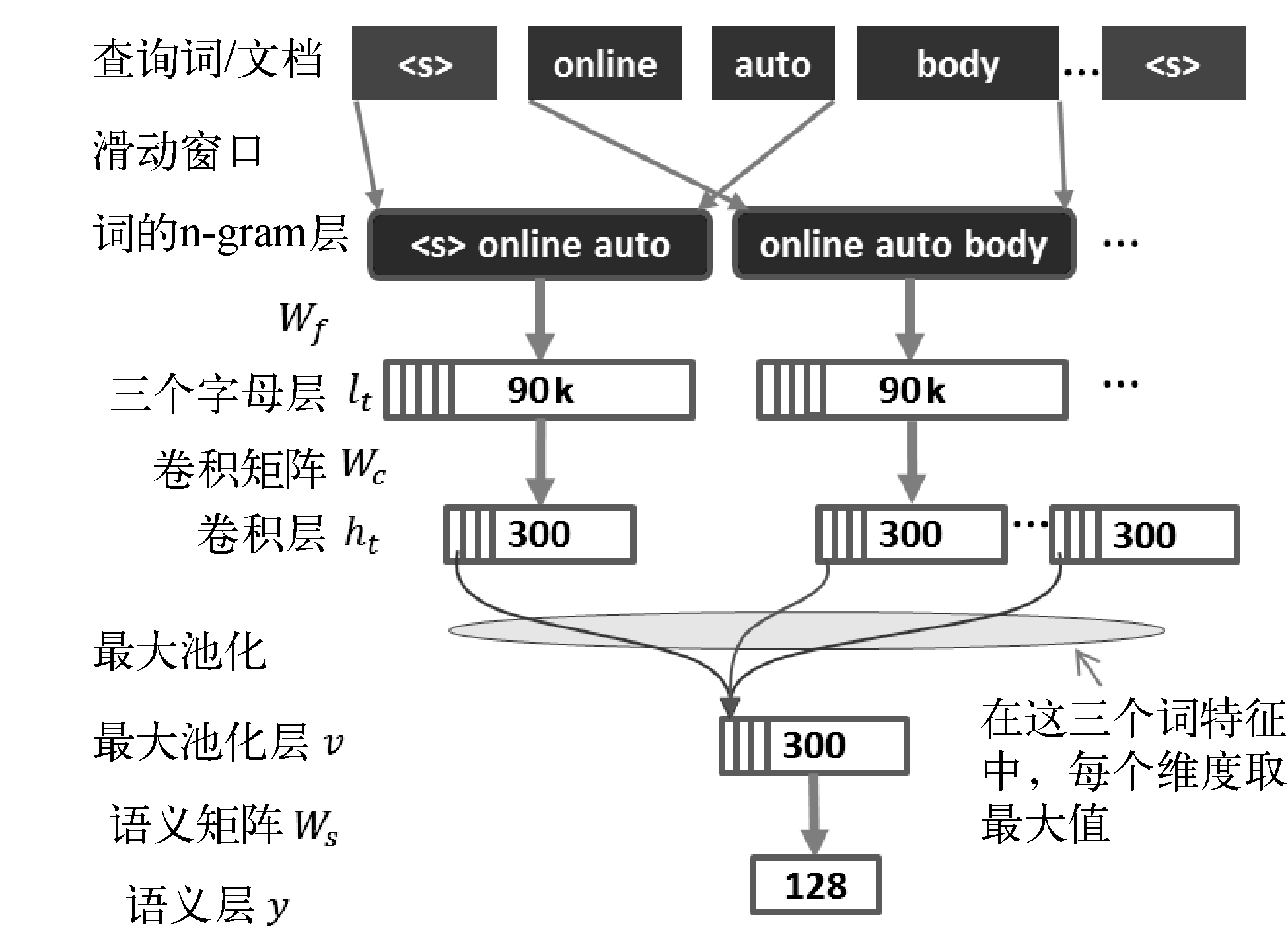
在DSSM基础上,CLSM增加了1维卷积和池化操作来获取句子全局信息,如图13所示。通过引入卷积操作,可以充分考虑窗口内上下文的影响,从而保证词在不同语境下的个性化语义。
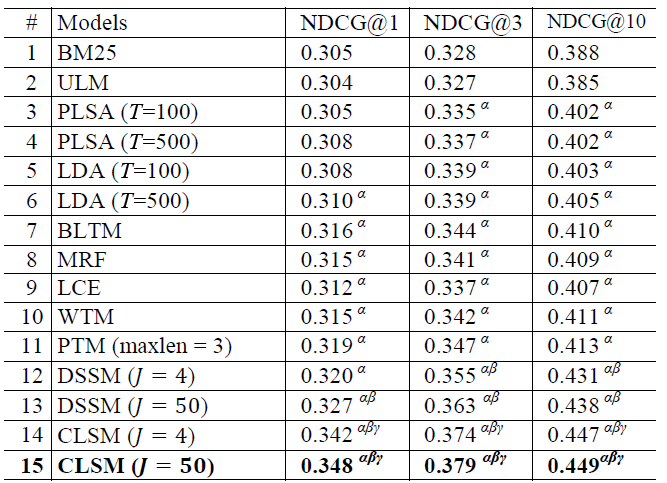
对应效果如图14所示:
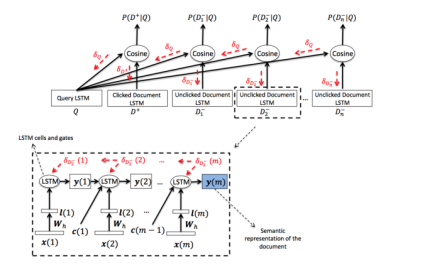
(3) LSTM-DSSM
LSTM-DSSM使用LSTM作为Q和D的表示,其他框架和DSSM一致,其网络结构图如图15所示。由于LSTM具备语义记忆功能且蕴含了语序信息,因此更适合作为句子的表示。当然也可以使用双向LSTM以及注意力模型(Attention Model)。
美团的深度学习文本匹配算法
文本的语义匹配作为自然语言处理经典的问题,可以用在搜索、推荐、广告等检索系统的召回、排序中,还可以用在文本的去重、归一、聚类、抽取等场景。语义匹配的常用技术和最新进展前文已经介绍了。
在美团这样典型的O2O应用场景下,结果的呈现除了和用户表达的语言层语义强相关之外,还和用户意图、用户状态强相关。用户意图即用户是来干什么的?比如用户在百度上搜索“关内关外”,其意图可能是想知道关内和关外代表的地理区域范围,“关内”和“关外”被作为两个词进行检索。而在美团上搜索“关内关外”,用户想找的可能是“关内关外”这家饭店,“关内关外”被作为一个词来对待。再说用户状态,一个在北京的用户和一个在武汉的用户,在百度或淘宝上搜索任何一个词条,他们得到的结果不会差太多。但是在美团这样与地理位置强相关的应用下就会完全不一样。比如在武汉搜“黄鹤楼”,用户找的可能是景点门票,而在北京搜索“黄鹤楼”,用户找的很可能是一家饭店。
如何结合语言层信息和用户意图、用户状态来做语义匹配呢?
在短文本外引入部分O2O业务场景相关特征,将其融入到设计的深度学习语义匹配框架中,通过点击/下单数据来指引语义匹配模型的优化方向,最终把训练出的点击相关性模型应用到搜索相关业务中。
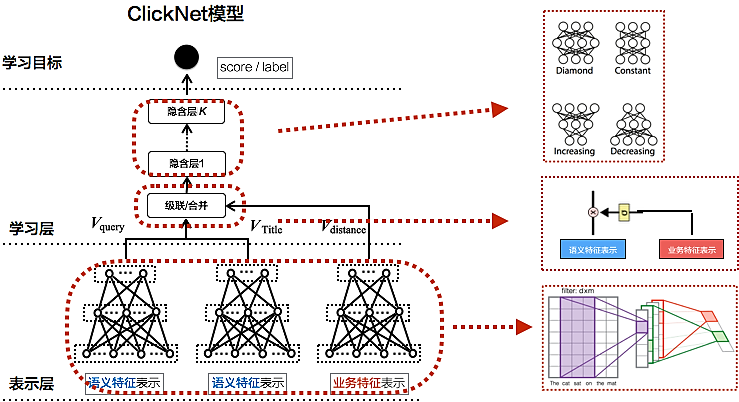
针对美团场景设计的点击相似度框架ClickNet,是比较轻量级的模型,兼顾了效果和性能两方面,能很好推广到线上应用,如图16所示。
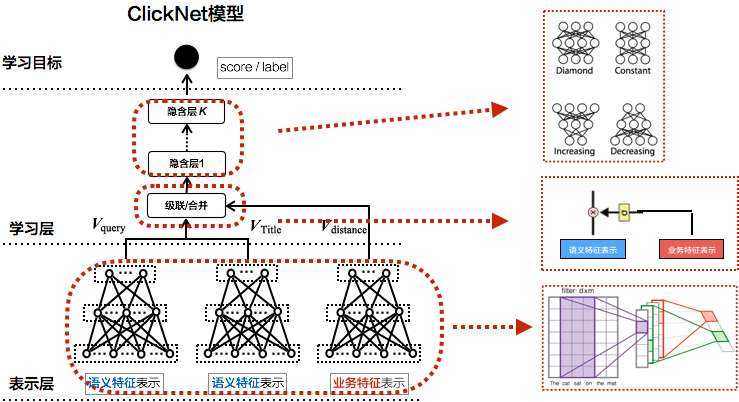
- 表示层。Query和商家名分别用语义和业务特征表示,其中语义特征是核心,通过DNN/CNN/RNN/LSTM/GRU方法得到短文本的整体向量表示。另外会引入业务相关特征,比如用户或商家的相关信息、用户和商家距离、商家评价等。
- 学习层。通过多层全连接和非线性变化后,预测匹配得分,根据得分和标签来调整网络,以学习出Query和商家名的点击匹配关系。
如果ClickNet算法框架上要训练效果很好的语义模型,还需要根据场景做模型调优。首先,我们从训练语料做很多优化,比如考虑样本不均衡、样本重要度等问题。其次,在模型参数调优时考虑不同的优化算法、网络大小层次、超参数的调整等问题。
经过模型训练优化,该语义匹配模型已经在美团平台搜索、广告、酒店、旅游等召回和排序系统中上线,使访购率/收入/点击率等指标有很好的提升。
总结一下,深度学习应用在语义匹配上,需要针对业务场景设计合适的算法框架。此外,深度学习算法虽然减少了特征工程工作,但模型调优的难度会增加。因此可以将框架设计、业务语料处理、模型参数调优三方面综合起来考虑,实现一个效果和性能兼优的模型。
基于深度学习的排序模型
排序模型简介
在搜索、广告、推荐、问答等系统中,由于需要在召回的大量候选集合中选择出有限的几个用于展示,因此排序是很重要的一环。如何设计这个排序规则使得最终业务效果更好呢?这就需要复杂的排序模型。比如美团搜索系统中的排序会考虑用户历史行为、本次查询Query、商家信息等多维度信息,抽取设计出各种特征,通过海量数据的训练得到排序模型。这里只简要回顾排序模型类型和演进,重点介绍深度学习用在排序模型中的情况。
排序模型主要分类三类:Pointwise、Pairwise、Listwise,如图17所示。Pointwise对单样本做分类或者回归,即预测 <Query, Doc> 的得分作为排序准则,比较有代表性的模型有逻辑回归、XGBoost。Pairwise会考虑两两样本之间偏序关系,转化成单分类问题,比如 <Query, Doc1> 比 <Query, Doc2> 高,那这个Pair预测正,反之则负,典型的模型有RankSVM、LambdaMART。第三类就是Listwise模型,排序整体作为优化目标,通过预测分布和真实排序分布的差距来优化模型,典型的模型如ListNet。
深度学习排序模型的演进
在排序模型的发展中,神经网络很早就被用来做排序模型,比如2005年微软研究院提出的RankNet使用神经网络做Pairwise学习;2012年谷歌介绍了用深度学习做CTR的方法;与此同时,百度开始在凤巢中用深度学习做CTR,于2013年上线。随着深度学习的普及,各大公司和研究机构都在尝试把深度学习应用在排序中,比如谷歌的Wide & Deep、YouTube的DNN推荐模型等,前面介绍的DSSM也可用来排序。下面将对RankNet、Wide & Deep、YouTube的排序模型作简单介绍。
RankNet
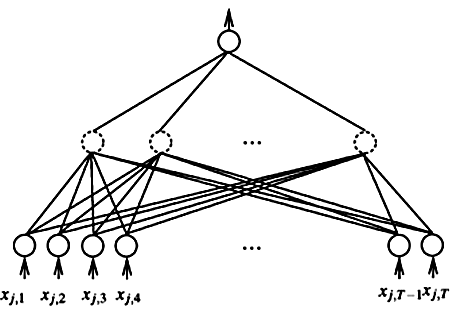
RankNet是Pairwise的模型,同样转化为Pointwise来处理。比如一次查询里,D和D有偏序关系,前者比后者更相关,那把两者的特征作为神经网络的输入,经过一层非线性变化后,接入Loss来学习目标。如果D比D更相关,那么预测的概率为下式,其中S和S是对应Doc的得分。
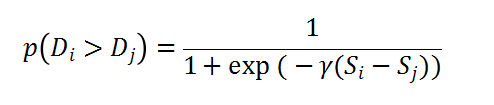
在计算得分时使用神经网络,如图18所示,每样本的输入特征作为第一层,经过非线性变换后得到打分,计算得到Pair的得分后进行反向传播更新参数,这里可以使用Mini-Batch。由于RankNet需要预测的概率公式具有传递性,即D和D的偏序概率可以由D和D以及D和D得到,因此RankNet把计算复杂度从O(n²)变成了O(n),具体介绍可参考文献。
当然,后续研究发现,RankNet以减少错误Pair为优化目标,对NDCG等指标(关心相关文档所在位置)衡量的效果不是太好,于是后面出现了改进模型,如LambdaRank。RankNet是典型的神经网络排序模型,但当时工业界用得多的还是简单的线性模型,如逻辑回归,线性模型通过大量的人工设计特征来提高效果,模型解释性好性能也高。当人工设计特征到一定程度就遇到了瓶颈,而深度学习能通过原始的特征学习出复杂的关系,很大程度减轻了特征工程的工作。并且GPU、FPGA等高性能辅助处理器变得普及,从而促进了深度神经网络做排序模型的广泛研究。
Wide&Deep
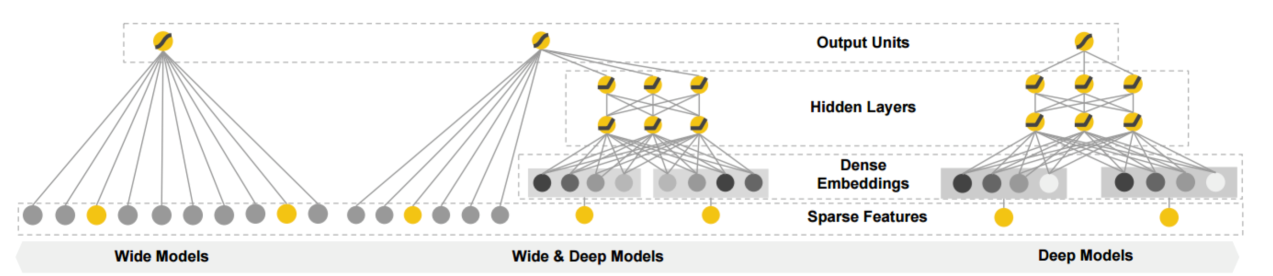
谷歌发表过一篇论文“Wide & Deep Learning”,其观点可以用在推荐里,比如谷歌的Apps推荐利用此观点取得很好的效果,并把模型发布在TensorFlow中。Wide & Deep整体模型结构分为Wide和Deep两部分,这两部分在最外层合并一起来学习模型,如图19所示。输入都是稀疏特征,但特征分为两种:一种适合做Deep的深度网络变化,适合时效性或者记忆性的特征,比如统计特征或者展示位置等;另一种可以直接连在最外层,适合有推广力但需要深度组合抽样的特征,比如品类、类型等。在模型优化时两部分做联合优化,Wide部分使用FTRL,而Deep使用Adagrad算法。这样,Wide和Deep对不同类型特征区分开来,充分发挥各自作用,解释性比较好。
这种思路其实可以做些扩展。比如Wide连接不是在最外层,而是在某一层,Deep的某些层也可以连接到最外层,这样能充分利用不同层抽象的Dense信息。与Wide & Deep的网络连接方式类似,如2003年NNLM和2010年RNNLM模型里的直接连接(Direct Connection),其浅层和深层的结合能很好地加速收敛,深度学习的Highway方式也是类似的。目前Wide & Deep应用较多,比如在阿里巴巴就有比较好的应用。
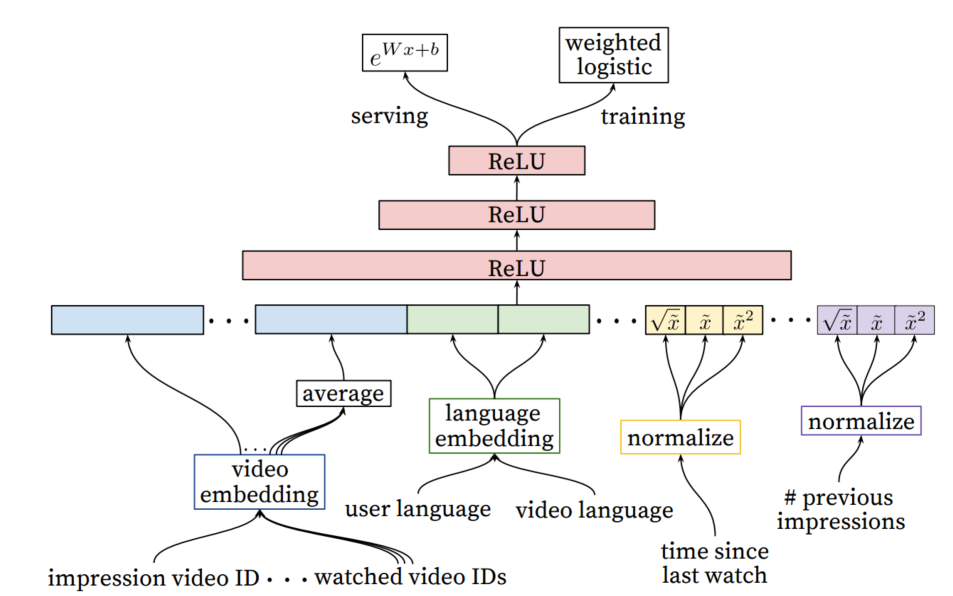
YouTube DNN排序模型
YouTube用来预测用户观看视频时长,转化为加权的逻辑回归问题。DNN排序模型和前面的工作类似,其网络结构是标准的前馈神经网络,如图20所示。DNN排序模型的特点还是在输入特征上。虽然深度学习模型对特征工程要求很低,但很多数据需要经过简单处理后才可加入模型。图20中的特征分为很多域,比如语言方面、视频方面、用户历史看过的视频ID,还有之前观看时长的统计量和归一化的值。离散值经过Embedding的处理后变成连续向量,再级联起来经过多层非线性变化后来预测最终的标签。
从上面介绍的深度学习相关排序模型可以看出,排序模型所需要的数据类型多种多样,数据的含义也各有不同,不同于图像、语音领域单一的输入形式。因此在做排序模型中,输入特征的选取和表示方式是很重要的,比如连续特征、离散特征处理、用户历史、文档特征的区分等。在美团场景中,设计排序模型需考虑业务特点,对输入特征的表示做很多尝试。
美团的深度学习排序模型尝试
在语义匹配模型中介绍了ClickNet框架,其实该框架同时也可用于排序,与语义匹配的区别主要在表示层,如图21所示。如果ClickNet用作搜索的CTR模型,那表示层的Query和Title的语义特征只是一部分,还有用户查询、用户行为、商家信息以及交叉组合特征都可以作为业务特征,并按特征的类型分不同的域。进一步讲,如果场景不包含语义匹配,模型的输入可以只有业务特征。下面简单讲解在美团用ClickNet做排序模型的尝试。
ClickNet-v1
ClickNet设计的初衷是它作为文本的匹配模型,并作为一维语义特征加入到业务的Rank模型中以提升效果。但根据上线之后的数据分析,我们发现以语义特征表示为主、辅以部分业务特征的ClickNet在排序系统中有更好的表现。我们针对排序模型做了如下改进。
- (1) 业务特征选取。从业务方Rank已有的人工特征中,选取O2O有代表性的且没经过高级处理过的特征,比如用户位置、商家位置、用户历史信息、商家评价星级、业务的季节性等。
- (2) 特征离散化。选取的业务特征做离散化处理,比如按特征区间离散化等。
- (3) 样本处理。针对业务需要对正负例采样,对点击、下单、付费做不同的加权操作。
- (4) 信息的融合。通过引入Gate来控制语义特征和各业务特征的融合,而不仅是求和或者级联,通过样本学习出Gate的参数。
针对业务Rank的目标优化ClickNet后,效果有很大改善,但模型还是偏重于语义特征。能否直接使用ClickNet做排序模型呢?答案是可以的。只需要加重业务特征、弱化或者去除语义表示特征就可以,这样修改后的模型就是ClickNet-v2。
ClickNet-v2
ClickNet-v2以业务特征为主,替换业务Rank模型为目标,使用业务特征作为ClickNet的表示层输入,通过对各特征离散化后传入模型。和ClickNet-v1不一样的是,ClickNet-v2业务特征种类繁多,需要做深度的分析和模型设计。
比如如何考虑位置偏好问题?因为展示位置会有前后顺序,后面的展示不容易被用户看到,从而天然点击率会偏低。一种解决思路是可以把位置信息直接连接到最外层,不做特征组合处理。
再比如各业务特征通过多层非线性变化后,特征组合是否充分?一种解决思路是使用多项式非线性变换,这能很好组合多层的特征。
又比如模型组合的效果是否更好?一种解决思路是尝试FM和ClickNet的级联,或者各模型的Bagging。
此外还有模型的解释性等很多和业务场景相关的情况需要考虑。
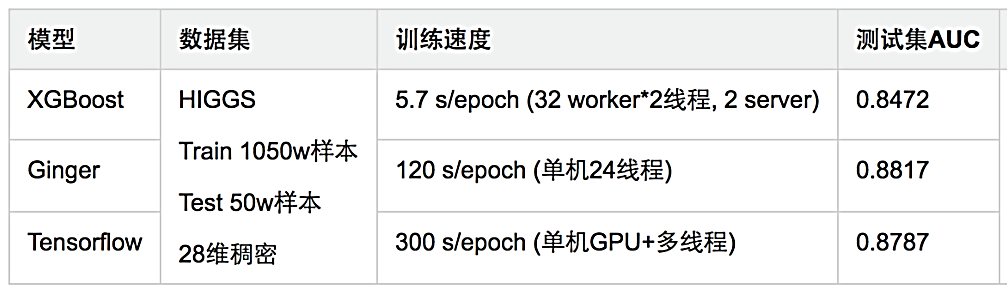
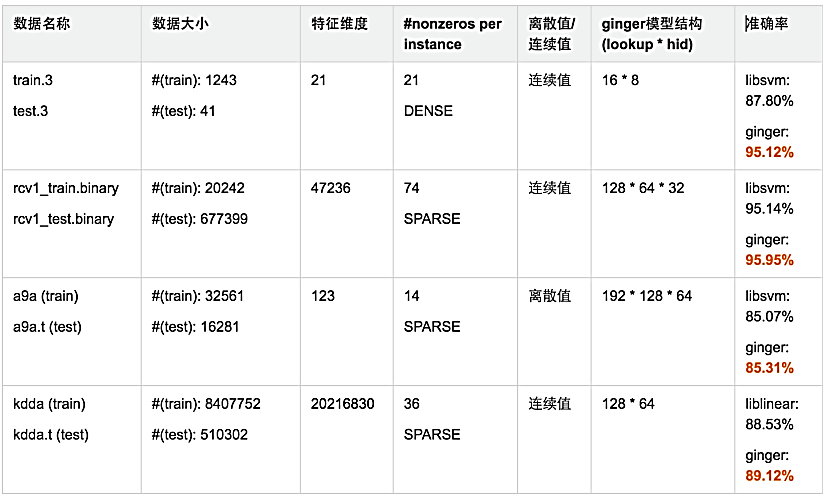
ClickNet是基于自研的深度学习框架Ginger实现的,收敛速度和效果都非常理想。我们来看看分类任务上的一些测试,如图22所示。在Higgs数据上,基于Ginger的ClickNet比基于XGBoost的AUC提升34个千分点,使用TensorFlow实现的ClickNet比基于Ginger的AUC差3个千分点,且其速度慢于Ginger。如图23所示,ClickNet相比线性模型,其准确率都有较好的提升。
总结
因为深度学习的拟合能力强、对特征工程要求低,它在文本领域已经有很多应用。本章以语义匹配和排序模型为例,分别介绍了业界进展和美团场景的应用。
第一部分介绍了语义匹配经历的向量空间、潜在语义分析、主题模型、深度学习几个阶段,重点介绍了深度学习应用在语义匹配上的Embedding和DSSM系列模型,以及美团尝试的ClickNet模型。第二部分介绍了深度学习在排序模型的一些进展和美团的一些尝试。除了这两部分内容外,深度学习几乎渗透了文本的各方面,美团还有很多尝试方式,比如情感分析、对话系统、摘要生成、关键词生成等,限于篇幅不做介绍。总之,认知智能还有很长的路需要走,语言文字是人类历史的文化沉淀,涉及语义、逻辑、文化、情感等众多复杂的问题。我们相信,深度学习在文本领域很快会有很大突破。
参考文献
- [1] Thomas Hofmann. “Probabilistic Latent Semantic Analysis”. 1999.
- [2] David M.Blei, Andrew Y.Ng, Michael Jordan. “Latent Dirichlet Allocation” . 2002.
- [3] Huang, Po-Sen et al. “Learning deep structured semantic models for web search using clickthrough data” in CIKM 2013.
- [4] Shen, Yelong, He, Xiaodong, Gao, Jianfeng, et al. “A latent semantic model with convolutional-pooling structure for information retrieval” in CIKM 2014.
- [5] H. Palangi et al. “Semantic modeling with long-short-term memory for information retrieval”. 2015.
团队简介
美团点评算法团队是整个美团点评技术团队的“大脑”,涵盖搜索、推荐、广告、智能调度、自然语言处理、计算机视觉、机器人以及无人驾驶等多个技术领域。帮助美团点评数亿活跃用户改善了用户体验,也帮助餐饮、酒店、结婚、丽人、亲子等200多个品类的数百万商户提升了运营效率。目前,美团点评算法团队在人工智能领域进行积极的探索和研究,不断创新与实践,致力于应用最前沿的技术,给广告大消费者带来更好的生活服务体验。
