

Solr Facet技术的应用与研究
问题背景
在《搜索引擎关键字智能提示的一种实现》一文中介绍过,美团的CRM系统负责管理销售人员的门店(POI)和项目(DEAL)信息,提供统一的检索功能,其索引层采用的是SolrCloud。在用户搜索时,如果能直观地给出每个品类的POI数目,各个状态的DEAL数目,可以更好地引导用户进行搜索,进而提升搜索体验。
需求分析
例如,下图是用户搜索项目(DEAL)的界面,当选中一个人或者组织节点后,需要实时显示状态分组和快捷分组的每个项的DEAL数目: 
为了实现上述导航效果,可以采用以下两个方案:
方案一, 针对每个导航项发送一个Ajax请求,去Solr服务器查询对应的DEAL数目。该方案问题在于,当导航项比较多时,扩展性不好。
方案二, 应用Solr自带的Facet技术实现以导航为目的的搜索,查询结果根据分类添加count信息。
DEAL的Solr索引设计如下:
schema.xml:
`<field name="deal_id" type="int" indexed="true" stored="true" />` //deal id
`<field name="title" type="text_ika" indexed="true" stored="false" />` //标题
`<field name="bd_id" type="int" indexed="true" stored="false" />` //负责人id
`<field name="begin_time" type="long" indexed="true" stored="false" />` //项目开始时间
`<field name="end_time" type="long" indexed="true" stored="false" />` //项目结束时间
`<field name="status" type="int" indexed="true" stored="false" />` //项目状态
`<field name="can_buy" type="boolean" indexed="true" stored="false" />` //是否可以购买
...省略
本文的例子中用于facet的字段有status,can_buy,begin_time,end_time
注: Facet的字段必须被索引,无需分词,无需存储。无需分词是因为该字段的值代表了一个整体概念,无需存储是因为一般而言用户所关心的并不是该字段的具体值,而是作为对查询结果进行分组的一种手段,用户一般会沿着这个分组进一步深入搜索。
Solr Facet简介
Facet是Solr的高级搜索功能之一,Solr作者给出的定义是导航(Guided Navigation)、参数化查询(Paramatic Search)。Facet的主要好处是在搜索的同时,可以按照Facet条件进行分组统计,给出导航信息,改善搜索体验。Facet搜索主要分为以下几类:
1. Field Facet 搜索结果按照Facet的字段分组并统计,Facet字段通过在请求中加入”facet.field”参数加以声明,如果需要对多个字段进行Facet查询,那么将该参数声明多次,Facet字段必须被索引。例如,以下表达式是以DEAL的status和can_buy属性为facet.field进行查询:
select?q=*:*&facet=true&facet.field=status&facet.field=can_buy&wt=json
Facet查询需要在请求参数中加入”facet=on”或者”facet=true”让Facet组件起作用,返回结果:
"facet_counts”: {
"facet_queries": {},
"facet_fields": { "status": [ "32", 96,
"0", 40,
"8", 81,
"16", 50,
"127", 80,
"64", 27 ] ,
"can_buy": [ "true", 236,
"false", 21 ]
},
"facet_dates": {},
"facet_ranges": {}
}
分组count信息包含在“facet_fields”中,分别按照"status"和“can_buy”的值分组,比如状态为32的DEAL数目有96个,能购买的DEAL数目(can_buy=true)是236。
Field Facet主要参数:
facet.field:Facet的字段
facet.prefix:Facet字段前缀
facet.limit:Facet字段返回条数
facet.offset:开始条数,偏移量,它与facet.limit配合使用可以达到分页的效果
facet.mincount:Facet字段最小count,默认为0
facet.missing:如果为on或true,那么将统计那些Facet字段值为null的记录
facet.method:取值为enum或fc,默认为fc,fc表示Field Cache
facet.enum.cache.minDf:当facet.method=enum时,参数起作用,文档内出现某个关键字的最少次数
2. Date Facet 日期类型的字段在索引中很常见,如DEAL上线时间,线下时间等,某些情况下需要针对这些字段进行Facet。时间字段的取值有无限性,用户往往关心的不是某个时间点而是某个时间段内的查询统计结果,Solr为日期字段提供了更为方便的查询统计方式。字段的类型必须是DateField(或其子类型)。需要注意的是,使用Date Facet时,字段名、起始时间、结束时间、时间间隔这4个参数都必须提供。 与Field Facet类似,Date Facet也可以对多个字段进行Facet。并且针对每个字段都可以单独设置参数。
3. Facet Query Facet Query利用类似于filter query的语法提供了更为灵活的Facet。通过facet.query参数,可以对任意字段进行筛选。
基于Solr facet的实现
本文的例子,需要查询DEAL的“状态”和“快捷选项”导航信息。由于,有的状态DEAL数目不仅与状态(status)字段有关,还与开始时间(begin_time)和(end_time)相关,且各个快捷选项的DEAL数目的计算字段各不相同,要求比较灵活的查询,所以本文拟采用Facet Query方式实现。 以下代码是采用solrJ构造facet查询对象的过程:
public SolrQuery buildFacetQuery(Date now) {
SolrQuery solrQuery = new SolrQuery();
solrQuery.setFacet(true);//设置facet=on
solrQuery.setFacetLimit(10);//限制facet返回的数量
solrQuery.setQuery("*:*");
long nowTime = now.getTime() / 1000;
long minTime = minTimeStamp;
long maxTime = maxTimeStamp;
solrQuery.addFacetQuery("status:0"); //待撰写
solrQuery.addFacetQuery("status:8"); //撰写中
solrQuery.addFacetQuery("status:16"); //已终审
solrQuery.addFacetQuery("status:32 AND " + "begin_time:[" + nowTime + " TO " + maxTime + " ]"); //已上架-待上线
solrQuery.addFacetQuery("status:32 AND " + "begin_time:[" + minTime + " TO " + nowTime + "] AND " + //已上架-上线中
"end_time:[" + nowTime + " TO " + maxTime + " ]");
solrQuery.addFacetQuery("status:32 AND " + "end_time:[" + minTime + " TO " + nowTime + "]"); //已上架-已下线
return solrQuery;
}
说明: "status:0" 查询满足条件的结果集中status=0的Deal数目, "status:32 AND " + "begin_time:[" + nowTime + " TO " + maxTime + " ]”,查询满足条件的结果集中,status=32且begin_time大于现在时间的Deal数目, 依次类推
返回结果:
"status:0":756,
"status:8":28,
"status:16":21,
"status:32 AND begin_time:[1401869128 TO 1956499199 ]":4,
"status:32 AND begin_time:[0 TO 1401869128] AND end_time:[1401869128 TO 1956499199 ]":41,
"status:32 AND end_time:[0 TO 1401869128]":10}
上述结果可知,“已上架-待上线”导航项对应的DEAL数为4个。
Solr Facet查询分析
1. Solr HTTP请求分发
当一个Restful(HTTP)查询请求到达SolrCloud服务器,首先由SolrDispatchFilter(实现javax.servlet.Filter)处理,该类负责分发请求到相应的SolrRequestHandler。具体分发操作在SolrDispatchFilter的doFilter方法中进行:
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain, boolean retry) {
......
handler = core.getRequestHandler( path );
if( handler == null && parser.isHandleSelect() ) {
if( "/select".equals( path ) || "/select/".equals( path ) ) {
solrReq = parser.parse( core, path, req );
String qt = solrReq.getParams().get( CommonParams.QT );
handler = core.getRequestHandler( qt ); //分发到相应的handler
.......
if( handler != null ) {
......
this.execute( req, handler, solrReq, solrRsp ); //处理请求
HttpCacheHeaderUtil.checkHttpCachingVeto(solrRsp, resp, reqMethod);
......
return;
}
}
}
protected void execute( HttpServletRequest req, SolrRequestHandler handler, SolrQueryRequest sreq, SolrQueryResponse rsp) {
sreq.getContext().put( "webapp", req.getContextPath() );
sreq.getCore().execute( handler, sreq, rsp );
}
接着,调用solrCore的execute方法:
public void execute(SolrRequestHandler handler, SolrQueryRequest req, SolrQueryResponse rsp) {
......
handler.handleRequest(req,rsp); // handler处理请求
postDecorateResponse(handler, req, rsp);
......
}
从上述代码逻辑可以看出,请求的实际处理是由SolrRequestHandler来完成的。
2. SolrRequestHandler处理过程
SolrRequestHandler的类继承结构,如下图所示: 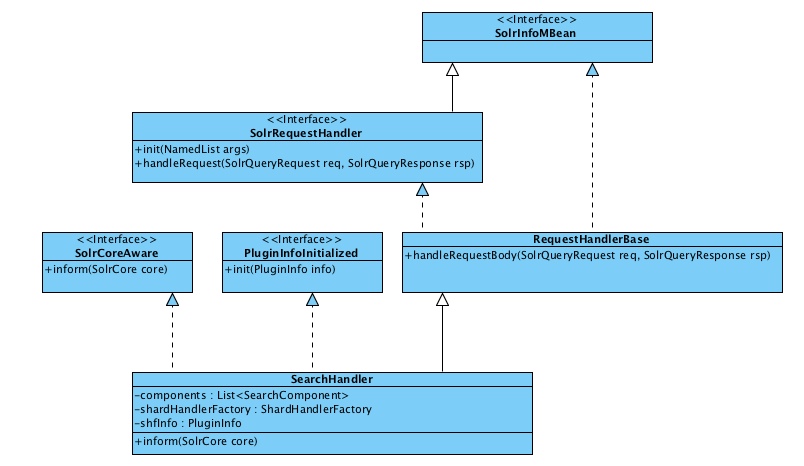
SolrRequestHandler请求处理器的接口,只有两个方法,一个是初始化信息,主要是配置时的默认参数,另一个就是处理请求的接口。 具体处理逻辑主要由SearchHandler类实现。
public interface SolrRequestHandler extends SolrInfoMBean {
public void init(NamedList args); //初始化信息
public void handleRequest(SolrQueryRequest req, SolrQueryResponse rsp); //处理请求
}
SearchHandler实现SolrRequestHandler,SolrCoreAware,在SolrCore初始化的过程中调用SolrRequestHandler中的inform(SolrCore core),首先是将solrconfig.xml里配置的各个处理组件按一定顺序组装起来,先是first-Component,默认的component,last-component,这些处理组件会按照它们的顺序来执行。如果没有配置,则加载默认组件,方法如下:
protected List`<String>` getDefaultComponents()
{
ArrayList`<String>` names = new ArrayList`<String>`(6);
names.add( QueryComponent.COMPONENT_NAME );
names.add( FacetComponent.COMPONENT_NAME );
names.add( MoreLikeThisComponent.COMPONENT_NAME );
names.add( HighlightComponent.COMPONENT_NAME );
names.add( StatsComponent.COMPONENT_NAME );
names.add( DebugComponent.COMPONENT_NAME );
names.add( AnalyticsComponent.COMPONENT_NAME );
return names;
}
SearchHandler中的component对象包含有QueryComponent、FacetComponent、HighlightComponent等,其中QueryComponent主要负责查询部分,FacetComponent处理facet、HighlightComponent负责高亮显示。SearchHandler在请求处理过程中,由SearchHandler.handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp)方法依次调用component的prepare、process、distributedProcess方法(分布式搜索本文暂不讨论) 。QueryComponent调用SolrIndexSearcher,SolrIndexSearcher继承了lucene的IndexSearcher类进行搜索,FacetComponent实现对Term的层面的统计,下图是SearchComponent的类图结构: 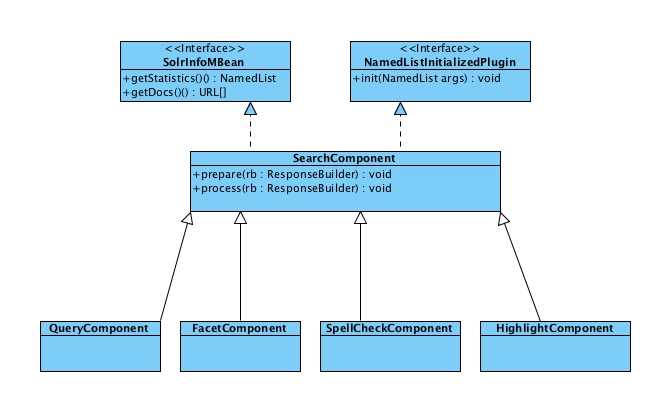
3. FacetComponent Facet查询分析
由上述分析可知,Solr的Facet功能实际上是由FacetComponent组件来实现的,具体实现在FacetComponent.process方法中:
public void process(ResponseBuilder rb) throws IOException
{
if (rb.doFacets) {
SolrParams params = rb.req.getParams();
SimpleFacets f = new SimpleFacets(rb.req, rb.getResults().docSet,params, rb ); //最终facet查询委托给SimpleFacets类进行处理
NamedList`<Object>` counts = f.getFacetCounts();
......
}
}
首先QueryComponent处理q参数里的查询,查询的结果的DocID保存在docSet里,这里是一个无序的document ID 的集合。然后把docSet封装在SimpleFacets中,调用SimpleFacets.getFacetCounts()获取统计结果:
public NamedList`<Object>` getFacetCounts() {
......
facetResponse = new SimpleOrderedMap`<Object>`();
facetResponse.add("facet_queries", getFacetQueryCounts());
facetResponse.add("facet_fields", getFacetFieldCounts());
facetResponse.add("facet_dates", getFacetDateCounts());
facetResponse.add("facet_ranges", getFacetRangeCounts());
......
return facetResponse;
}
由上可知,返回给客户端的结果有四种类型facet_queries、facet_fields、facet_dates、facet_ranges,分别调用getFacetQueryCounts(),getFacetFieldCounts(),getFacetDateCounts(),getFacetRangeCounts()完成查询。
4. getFacetQueryCounts统计count过程
由于篇幅原因,上述四个方法不一一展开分析,本文用到的查询主要是Facet Query,下面分析一下getFacetQueryCounts方法源码:
public NamedList`<Integer>` getFacetQueryCounts() throws IOException,SyntaxError {
NamedList`<Integer>` res = new SimpleOrderedMap`<Integer>`();
String[] facetQs = params.getParams(FacetParams.FACET_QUERY);
if (null != facetQs && 0 != facetQs.length) {
for (String q : facetQs) { // 循环统计每个facet query的count
parseParams(FacetParams.FACET_QUERY, q);
Query qobj = QParser.getParser(q, null, req).getQuery();
if (qobj == null) {
res.add(key, 0);
} else if (params.getBool(GroupParams.GROUP_FACET, false)) {
res.add(key, getGroupedFacetQueryCount(qobj));
} else {
res.add(key, searcher.numDocs(qobj, docs)); //
}
}
}
return res;
}
该方法的返回类型NamedList是一个有序的name/value容器,保存每个facet query和对应的count值。由代码可知,在for循环体中逐个统计facet query的count值,其中,parseParams方法中把”key”设置成本次循环的facet query变量“q“,由于GroupParams.GROUP_FACET的值是false(group类似与mysql的group by功能,一般不会打开),所以count值实际是由searcher.numDocs(qobj, docs)方法负责计算,这里的searcher类型是SolrIndexSearcher。
SolrIndexSearcher的numDocs方法源码如下:
public int numDocs(Query a, DocSet b) throws IOException {
if (filterCache != null) {
Query absQ = QueryUtils.getAbs(a); //如果为negative,则返回相应的补集
DocSet positiveA = getPositiveDocSet(absQ); //查询absQ 获取docSet集合
return a==absQ ? b.intersectionSize(positiveA) : b.andNotSize(positiveA);
} else {
TotalHitCountCollector collector = new TotalHitCountCollector();
BooleanQuery bq = new BooleanQuery();
bq.add(QueryUtils.makeQueryable(a), BooleanClause.Occur.MUST);
bq.add(new ConstantScoreQuery(b.getTopFilter()), BooleanClause.Occur.MUST);
super.search(bq, null, collector);
return collector.getTotalHits();
}
}
参数a传入facet query对象,参数b传入经过QueryComponent组件处理后得到DocSet集合。DocSet存储的是无序的文档标识号(ID),ID并不是我们在schema.xml里配置的unique key,而是Solr内部的一个文档标识,其次,DocSet还封装了集合运算的方法,如“求交集”、”求差集”。
由于,我们在solrconfig.xml中配置了filterCache:
`<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0”/>`
于是,numDocs方法中filterCache对象不为null,运行到下面三行代码:
Query absQ = QueryUtils.getAbs(a); //如果为negative,则返回相应的补集
DocSet positiveA = getPositiveDocSet(absQ); //查询absQ 获取docSet集合
return a==absQ ? b.intersectionSize(positiveA) : b.andNotSize(positiveA); //集合运算
首先,通过QueryUtils.getAbs(a)将查询对象a统一转化为一个“正向查询对象”absQ,getPositiveDocSet(absQ)方法查询absQ对应的DocSet集合:getPositiveDocSet方法首先查询filterCache中是否存在absQ查询对象对应的结果,存在,则直接返回结果,否则,从索引中查询并把结果保存到filterCache中。
接下来进行集合运算,如果Query对象a和absQ是同一个对象,表明本次查询是“正向查询”,则进行”交集“运算b.intersectionSize(positiveA),否则进行”差集“运算,最终返回结果集的size。由此可见,facet query对应的count值是集合交集和差集运算后的集合的size。
BTW,如果没有用到filterCache,会每次都构造一个BooleanQuery查询对象到索引中去查询。
5. FacetComponent Facet排序 Solr的FacetComponet支持两种排序: count和index。count是按每个词出现的次数,index是按词的字典顺序。如果查询参数不指定facet.sort,Solr默认是按count排序。排序功能是在FacetComponet的finishStage方法中完成的,详见源码。
总结
本文介绍了Solr Facet技术,并在此基础上实现了DEAL搜索的导航功能,然后从源码级别分析了Solr处理Facet请求的详细过程。
参考资料
- SimpleFacetParameters http://wiki.apache.org/solr/SimpleFacetParameters
- 使用Apache Lucene和Solr 4实现下一代搜索和分析 http://www.ibm.com/developerworks/cn/java/j-solr-lucene/
- Faceted Search with Solr http://searchhub.org/2009/09/02/faceted-search-with-solr/
