

美团服务体验平台对接业务数据的最佳实践-海盗中间件
背景
移动互联网时代,用户体验为王。美团服务体验平台希望能够帮助客户解决在选、购、用美团产品过程中遇到的各种问题,真正做到“以客户为中心”,为客户排忧解难。但服务体验平台内部只维护客户的客诉数据,为了精准地预判和更好地解决客户遇到的问题,系统必须依赖业务部门提供的一些业务数据,包括但不限于订单数据、退款数据、产品数据等等。 本文会着重讲一下在整个系统交互过程中遇到的一些问题,然后分享一下在实践中探索出来的经验和方法论,希望能够给大家带来一些启发。
问题
对接场景广而杂
首先,需要接入服务体验平台服务(包括直接面向用户的C端服务、面向客服的工单服务等等)的业务方非常多且杂,而且在不断拓展。美团有非常多的业务线,比如外卖、酒店、旅游、打车、交通、到店餐饮、到店综合、猫眼等等。其中部分业务又延展出多条子业务线,比如大交通部门包含火车票、汽车票、国内机票、国际机票、船票等等。具体到每一条子业务线的每一个业务场景,客户都有可能会遇到问题。对于这些场景,服务体验平台服务都需要调用对应的业务数据接口,来帮助用户自助或者客服协助解决这些问题。就美团现有的业务而言,这样的场景数量会达到万级。而且业务形态在不断迭代,还会有更多的场景被挖掘出来,这些都需要持续对接更多的业务数据来进行支撑。
接入场景定制化要求高
其次,接入服务体验平台服务的业务方定制化要求很高。因为业务场景的差异化非常大,不同的接入方都希望能够定制特殊复杂逻辑,需要服务体验平台提供的服务解决方案与业务深度耦合。这就需要服务体验平台侧对接入方业务逻辑和数据接口深入了解,并对这些业务数据进行组装,针对每个场景进行定制开发。
方案
早期方案
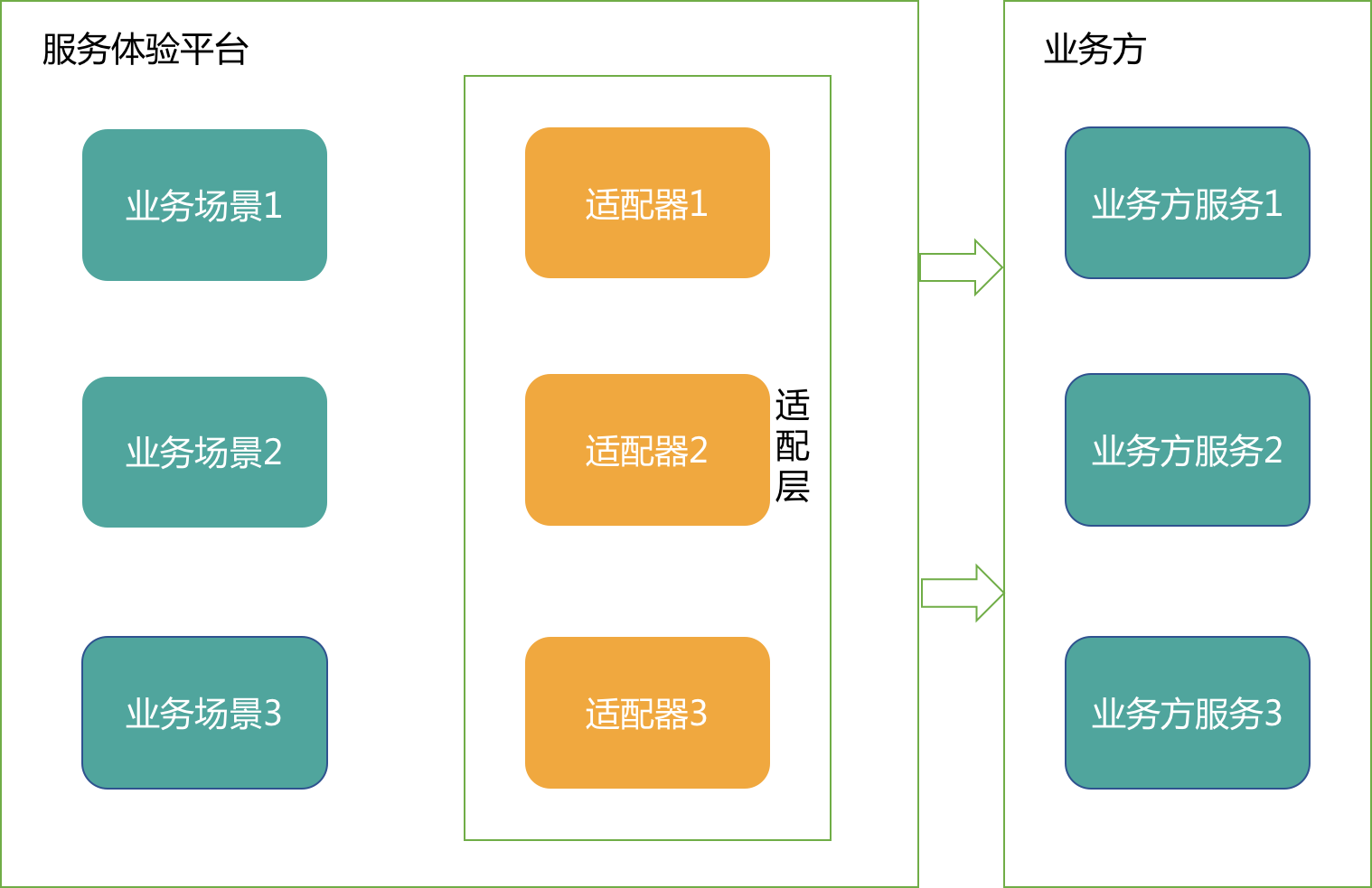
为了解决上述问题,初期在做系统设计时候,考虑业务方多是既有系统,所以服务体验平台服务趋向平台化设计,并引入了适配层。服务体验平台内部对所有的业务数据和逻辑进行统一抽象,对内标准化接口,屏蔽掉业务逻辑和接口的差异。所有的定制化逻辑都在适配层中封装。但这需要客服侧RD对所有的场景去编写适配器代码,将从一个或者多个业务部门接口中拿到的业务数据,转成内部实际场景需要的数据。
其系统交互如下图所示:
缺点
虽然上述系统设计能满足业务上的要求,但是存在两个比较明显的缺点。
编码工作量繁重
如上图所示,每个业务场景都需要编写适配器来满足需求,如果依赖的外部接口比较少,场景也比较单一,按照上述方案实施还可以接受。但业务接入非常多且杂,给客服侧RD带来了非常繁重的工作量,包括适配器编写以及后续维护过程中对下游业务接口的持续跟踪和监控。
客服侧RD需要深入了解业务方逻辑
另外,由于客服侧RD对于业务模型的不熟悉,解析业务模型然后组装最终展示给客户的数据,需要比业务方RD花更多的时间来梳理和实现,并且花费更多的时间来验证正确性。比如下面是一个真实的组装业务接口并对业务数据进行处理的案例:
public class TicketAdapterServiceImpl implements OrderAdapterService {
@Resource(name = "tradeQueryClient")
private TradeTicketQueryClient tradeTicketQueryClient;
@Resource
private ColumbusTicketService columbusTicketService;
/**
* 根据订单ID获取门票相关的订单数据、门票数据、退款数据等
**/
@Override
public OrderInfoDTO handle(OrderRequestDTO orderRequestDTO) {
List<ITradeTicketQueryService.TradeDetailField> tradeDetailFieldList = new ArrayList<ITradeTicketQueryService.TradeDetailField>();
tradeDetailFieldList.add(ITradeTicketQueryService.TradeDetailField.ORDER);
tradeDetailFieldList.add(ITradeTicketQueryService.TradeDetailField.TICKET);
tradeDetailFieldList.add(ITradeTicketQueryService.TradeDetailField.REFUND_REQUEST);
try {
//通过接口A得到部分订单数据、门票数据和退款数据
RichOrderDetail richOrderDetail = tradeTicketQueryClient.getRichOrderDetailById(orderRequestDTO.getOrderId(), tradeDetailFieldList);
if (richOrderDetail == null) {
return null;
}
if (richOrderDetail.getOrderDetail() == null) {
return null;
}
OrderDetail orderDetail = richOrderDetail.getOrderDetail();
RefundDetail refundDetail = richOrderDetail.getRefundDetail();
OrderInfoDTO orderInfoDTO = new OrderInfoDTO();
//解析和处理接口A返回的字段,得到客服侧场景真正需要的数据
orderInfoDTO.put("dealId", orderDetail.getMtDealId());
orderInfoDTO.put(DomesticTicketField.VOUCHER_CODE.getValue(), getVoucherCode(richOrderDetail));
orderInfoDTO.put(DomesticTicketField.REFUND_CHECK_DUE.getValue(), getRefundCheckDueDate(richOrderDetail));
orderInfoDTO.put(DomesticTicketField.REFUND_RECEIVED_DUE.getValue(), getRefundReceivedDueDate(richOrderDetail));
//根据接口B获取另外一些订单数据、门票详情数据、退款数据
ColumbusTicketDTO columbusTicketDTO = columbusTicketService.getByDealId((int) richOrderDetail.getOrderDetail().getMtDealId());
if (columbusTicketDTO == null) {
return orderInfoDTO;
}
//解析和处理接口B返回的字段,得到客服侧场景真正需要的数据
orderInfoDTO.put(DomesticTicketField.REFUND_INFO.getValue(), columbusTicketDTO.getRefundInfo());
orderInfoDTO.put(DomesticTicketField.USE_METHODS.getValue(), columbusTicketDTO.getUseMethods());
orderInfoDTO.put(DomesticTicketField.BOOK_INFO.getValue(), columbusTicketDTO.getBookInfo());
orderInfoDTO.put(DomesticTicketField.INTO_METHOD.getValue(), columbusTicketDTO.getIntoMethod());
return orderInfoDTO;
} catch (TException e) {
Cat.logError("查询不到对应的订单详情", e);
return null;
}
}
}
探索
将适配层交由业务方实现
为了克服早期方案的两个缺点,最初,我们希望能够把场景数据的准备和业务模型的解析工作,都交给对业务比较熟悉的团队来处理,即将适配层交由业务方来实现。
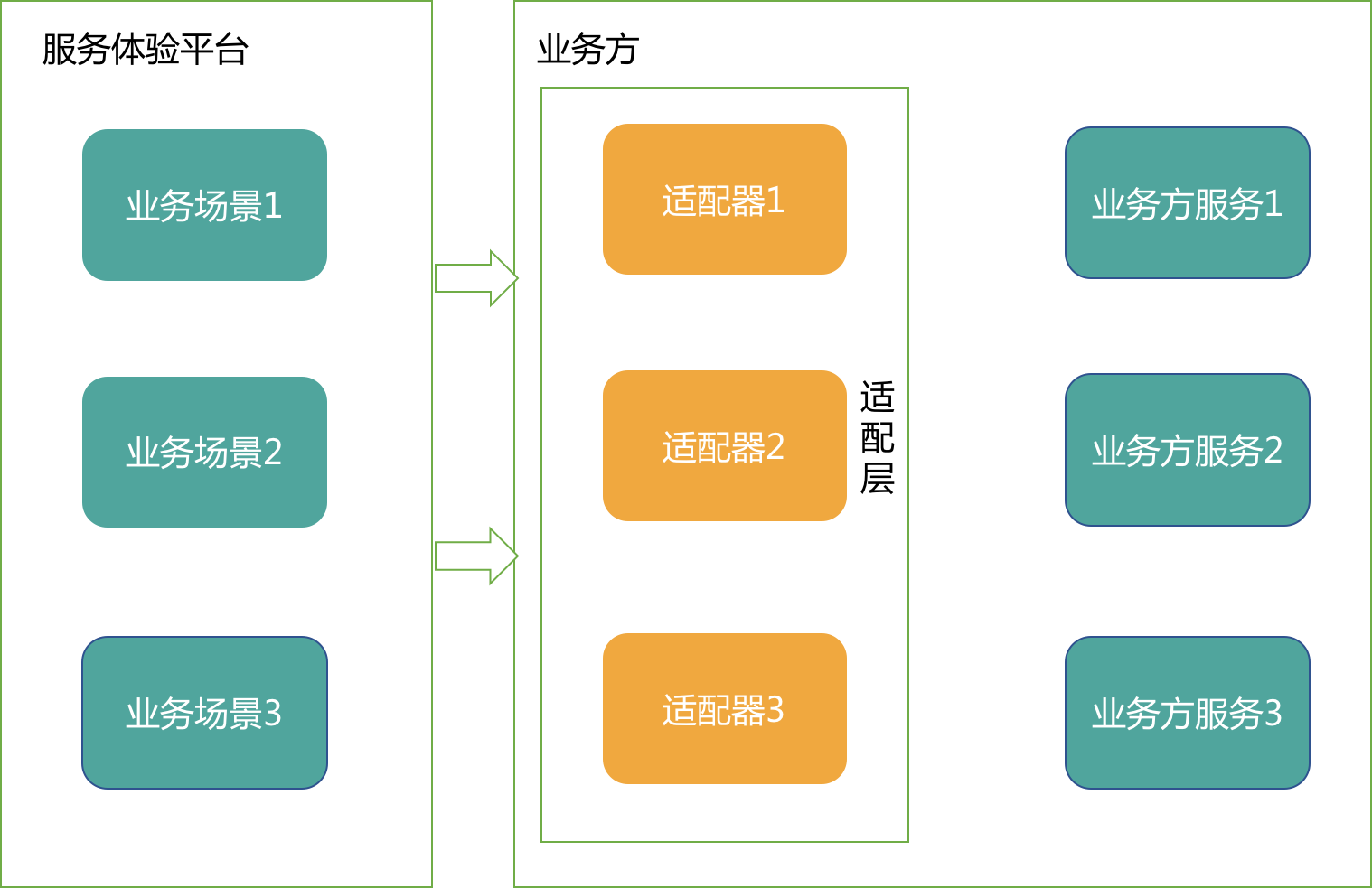
这样做的话优势和劣势也比较明显。
优势
客服这边关注自己的领域服务就好,做好平台化,数据提供都交给业务团队,解放了客服侧RD。
劣势
但对业务方来说带来了比较大的工作量,业务方既有服务的复用性很低,对客服侧每一个需要数据的场景,都要重新封装新的服务。
更好的解决方案?
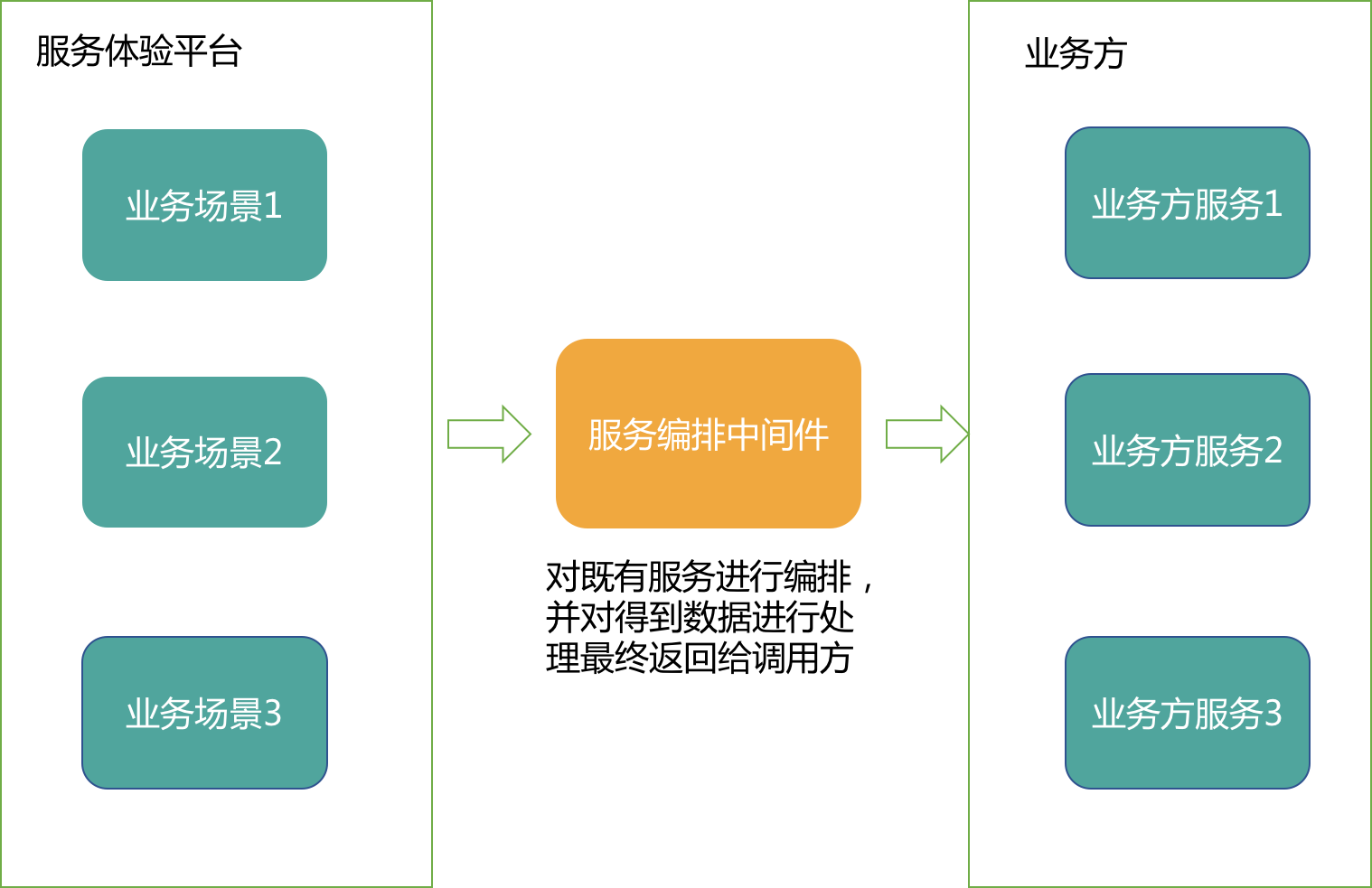
这个时候我们思考:是否可以既能让业务方解析自己的业务数据,又能够尽量利用既有服务呢?我们考虑把既有服务的组装过程以及模型的转换都让一个服务编排的中间件来实现。但是使用这个中间件有一个前提,就是业务方提供出来的既有服务必须支持泛化调用,避免调用方直接依赖服务方客户端(文章下一个小节也会补充下对于泛化调用的解释)。其交互模型如下图所示:
结果-海盗中间件
简介
什么是海盗?
海盗就是一个用来对支持泛化调用(上述所说)的服务进行编排,然后获取预期结果的一个中间件。使用该中间件调用方可以根据场景来对目标服务进行编排,按需调用。
何为泛化调用?
通常服务提供方提供的服务都会有自己的接口协议,比如一个获取订单数据的服务:
package com.dianping.demo;
public interface DemoService{
OrderDTO getById(String orderId);
}
而调用方调用该服务需要引入该接口协议,即依赖该服务提供的JAR包。如果调用方需要集成多方数据,那就需要依赖非常多的API,同时服务方接口升级客户端也需要随之进行升级。而泛化调用就可以解决这个问题,通过泛化调用客户端可以在服务方没有提供接口协议和不依赖服务方API的情况下对服务进行调用,通过类似GenericService这样一个接口来处理所有的服务请求。
如下是一个泛化调用的Demo:
public class DemoInvoke{
public void genericInvoke(){
/** 调用方配置 **/
InvokerConfig<GenericService> invokerConfig = new InvokerConfig("com.dianping.demo.DemoService", com.dianping.pigeon.remoting.common.service.GenericService.class);
invokerConfig.setTimeout(1000);
invokerConfig.setGeneric(GenericType.JSON.getName());
invokerConfig.setCallType("sync");
/** 泛化调用 **/
final GenericService genericService = ServiceFactory.getService(invokerConfig);
List<String> paramTypes = new ArrayList<String>();
paramTypes.add("java.lang.String");
List<String> paramValues = new ArrayList<String>();
paramValues.add("0000000001");
String result = genericService.$invoke("getById", paramTypes, paramValues);
}
}
有了这个泛化调用的前提,我们就可以重点去思考如何对服务进行编排,然后对取得的结果进行处理了。
DSL设计
首先重新梳理一下海盗的设计目标:
- 对既有服务进行编排调用
- 对获取的数据进行处理
而为了实现服务编排,需要定义一个数据结构来描述服务之间的依赖关系、调用顺序、调用服务的入参和出参等等。之后对获取的结果进行处理,也需要在这个数据结构中具体描述对什么样的数据进行怎么样的处理等等。
所以我们需要定义一套DSL(领域特定语言)来描述整个服务编排的蓝图,其语法如下:
{
//定义好需要调用的接口以及接口之间的依赖关系,一个接口调用即为一个task
"tasks": [
//第一个task
{
"url": "http://helloWorld.test.hello", //url 为pigeon发布的远程服务地址:
"alias": "d1", //别名,结果取值的时候可以通过别名引用
"taskType": "PigeonGeneric", //task的类别一般可以设置为PigeonGeneric,默认是pigeonAgent方式。
"method": "getByDoubleRequest", //要调用的pigeon接口的方法名
"timeout": 3000, //task的超时时间
"inputs": { //入参情况,多个入参通过key:value的结构书写,key的类别通过下面的inputsExtra定义。
"helloWorld": {
"name": "csophys", //可以通过#orderId,从上下文中获取值,可以通过$d1.orderId的形式从其他的task中获取值
"sex": "boy"
},
"name": "winnie"
},
"inputsExtra": { //入参key的类别定义
"helloWorld": "com.dianping.csc.pirate.remoting.pigeon.pigeon_generic_demo_service.HelloWorld",
"name": "java.lang.String"
}
},
//另一个task
{
"url": "http://helloWorld.test.hello",
"alias": "d2",
"taskType": "PigeonGeneric",
"method": "getByDoubleRequest",
"inputsExtra": {
"helloWorld": "com.dianping.csc.pirate.remoting.pigeon.pigeon_generic_demo_service.HelloWorld",
"name": "java.lang.String"
},
"timeout": 3000,
"inputs": {
"helloWorld": {
"name": "csophys",
"sex": "boy"
},
"name": "winnie"
}
}
],
"name": "pigeonGenericUnitDemo", //DSL的名称定义,暂时没有特别含义
"description": "pigeon泛型调用测试", //DSL的描述
"outputs": { //定义好最后输出的数据模型
"d1name": "$d1.name",
"languages": "$d2.languages",
"language1": "$d2.languages[0]",
"name": "csophys"
}
}
架构设计
有了DSL来描述整个编排蓝图之后,海盗自然要对该DSL进行解析,然后对服务进行具体调用。其整体架构如下所示:
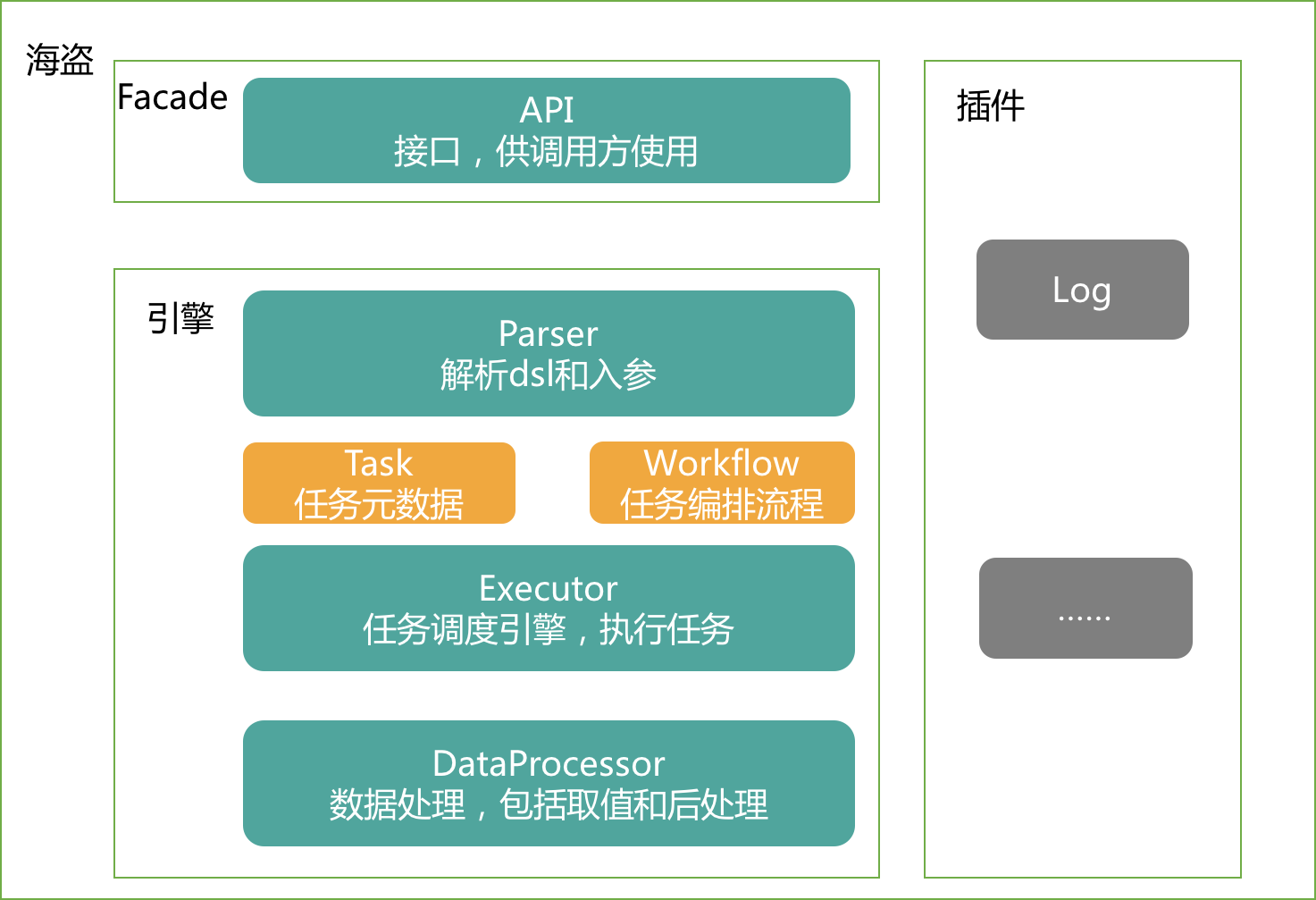
其中涉及到几个重点概念:
- Facade:对外提供统一接口,供客户端调用。
- Parser:对于输入的DSL进行解析,解析成内部流转的数据结构,同时得到所有的task,并且构建task调用逻辑树。
- Executor:真实发起调用的模块,目前支持平台内部的Pigeon和MTThrift调用方式,同时对HTTP等其他协议有良好的扩展性。
- DataProcessor:数据后处理。这边会把所有接口拿到的数据转换层客服场景这边需要的数据,并且通过设计的一些内部函数,可以支持一些如数据半脱敏等功能。
- 组件插件化:对日志等功能实现可插拔,调用方可以自定义这些组件,即插即用。
主要Feature
海盗具有如下主要特点:
- 采用去中心化的设计思路,引擎集成在SDK中。方案通用化,每一个需要业务数据的场景都可以通过海盗直接调用数据提供方。
- 服务编排支持并行和串行调用,使用方可以根据实际场景自己构造服务调用树。通过DSL的方式把之前硬编码组装的逻辑实现了配置化,然后通过海盗引擎把能并行调用的服务都执行了并行调用,数据使用方不用再自己处理性能优化。
- 使用JSON DSL 描述整个工作蓝图,简单易学。
- 支持JSONPath语法对服务返回的结果进行取值。
- 支持内置函数和自定义指令(语法参考ftl)对取到的元数据进行处理,得到需要的最终结果。
- 编排服务树可视化。
- 目前集团内部RPC中间件包括Pigeon、MTThrift,已进行了泛化调用支持,可以通过海盗实现Pigeon服务和MTThrift的服务编排。不需要限制业务团队的服务提供方式,但需要升级中间件版本。这里特别感谢服务治理团队的大力支持。
Tutorial
场景:需要根据订单ID查询订单状态和支付状态,但目前没有现成的接口支持该功能,但有两个既有接口分别是:
- 接口1:根据订单ID,获取到订单状态和支付流水号
- 接口2:根据支付流水号获取支付状态
那我们可以对这两个接口进行编排,编写DSL如下:
{
"tasks": [
{
"url": "http://test.service",
"alias": "d1",
"taskType": "PigeonGeneric",
"method": "getByOrderId",
"timeout": 3000,
"inputs": {
"orderId": "#orderId"
},
"inputsExtra": {
"name": "java.lang.String"
}
},
{
"url": "http://test.service",
"alias": "d2",
"taskType": "PigeonGeneric",
"method": "getPayStatus",
"timeout": 3000,
"inputs": {
"paySerialNo": "$d1.paySerialNo"
},
"inputsExtra": {
"time": "java.lang.String"
}
}
],
"name": "test",
"description": "组装上述接口获取订单状态和支付状态",
"outputs": {
"orderStatus": "$d1.orderStatus",
"payStatus": "$d2.payStatus"
}
}
然后客户端进行调用:
String DSL = "上述DSL文件";
String params = "{\"orderId\":\"000000001\"}";
Response resp = PirateEngine.invoke(DSL, params);
最后得到的数据即为调用场景真正需要的数据:
{
"orderStatus":1,
"payStatus":2
}
开发流程变化
因为获取数据的架构产生了变化,开发流程也随之发生改变。
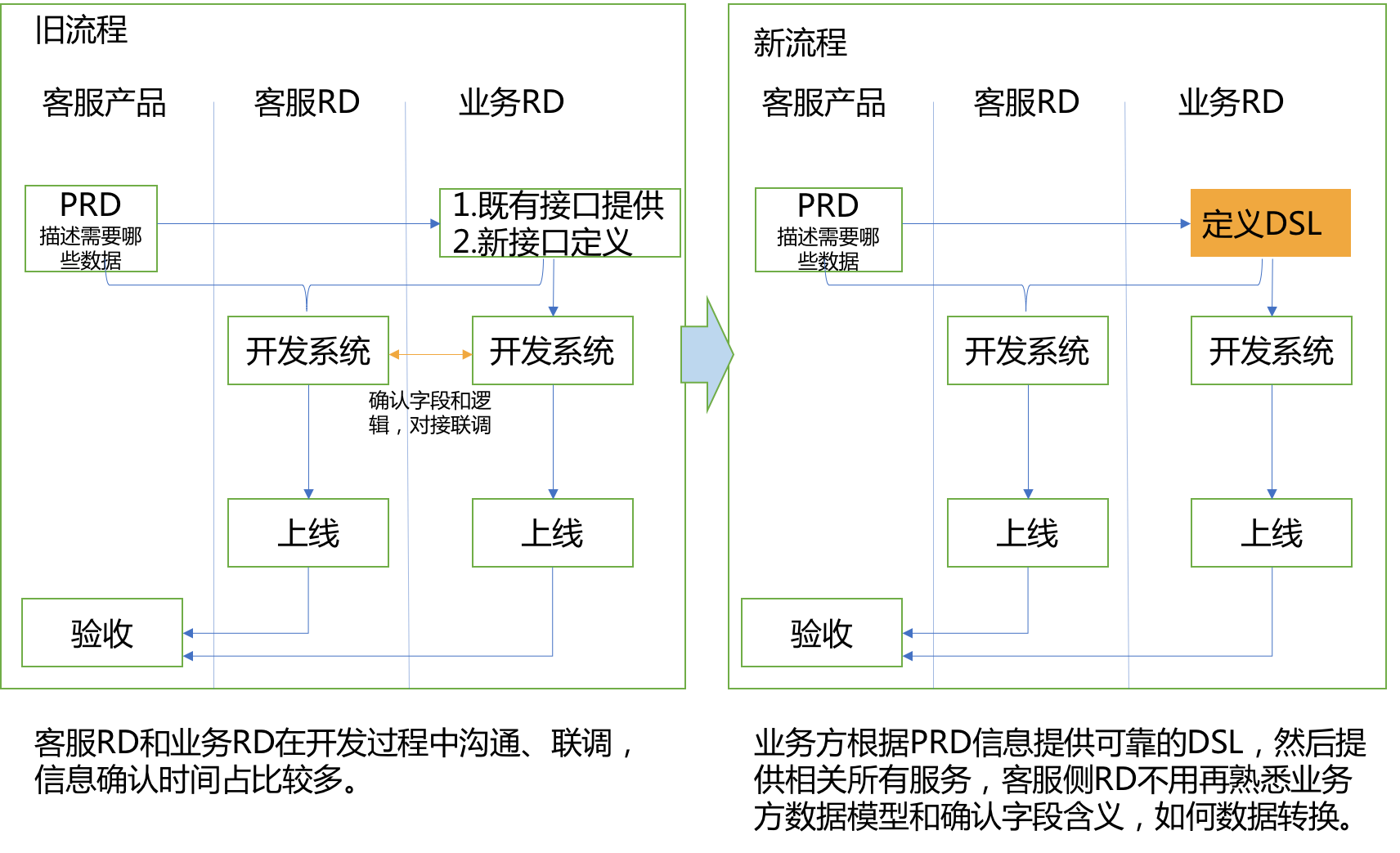
如图所示,因为减少了客服侧RD不断去向业务方RD确认返回的数据含义和逻辑,双方RD各自专注各自熟悉的领域,开发效率和最终结果准确性都有显著提升。
总结和展望
最后总结一下使用海盗之后的优势
- 去中心化的设计,可用性得到保证。
- 服务复用性高,领域划分更加清晰,让RD专注在自己熟悉的领域,降低研发成本。
- 因为流程变化后,业务方可以提前验证提供的数据,高质量交付。
- 客服侧对数据获取进行统一收口,可以对所有调用服务统一监控并对数据统一处理。
展望
海盗的技术规划:
- 丰富内部函数和运算表达式:目前海盗提供了一部分简单的内部函数用来对取到的值进行简单处理,同时正在实现支持调用方自定义运算表达式来支持复杂场景的数据处理,这部分需要持续完善。
- 屏蔽远程调用协议异构性:目前海盗只支持对美团Pigeon和MTThrift服务进行编排,这里要对协议进行扩展,支持类似HTTP等通用协议,同时支持调用方自定义协议和调用实现。
- 运营工具完善:提供一个比较完整的运营工具,调用方可以自行配置DSL并进行校验,然后一键调用查询最终结果。同时调用方可以通过该工具进行日志、报表等相关数据查询。
- 自动生成单元测试:能够把经过验证的DSL生成相应的单元测试用例给到数据提供方,持续保障提供的DSL的可用性和正确性。
作者简介
- 王彬,美团资深研发工程师,毕业于南京大学,2017年2月加入美团。目前主要专注于智能客服领域,从事后端工作。
- 陈胜,海盗项目负责人,智能客服技术负责人,2013年加入大众点评。在未来智能客服组会持续在平台化和垂直领域方向深入下去,为消费者、商家、企业提供更加智能的客户服务体验。
招聘广告
服务体验平台可以深入接触到公司的所有业务,推进业务改善产品。提升客户的服务体验。打造一个客户贴身的智能服务助手。通过技术的手段更快地解决客户的问题,并且最大程度地节省客服的人力成本。欢迎有意向的同学加入服务体验平台,上海、北京都有需求。简历请投递至:sheng.chen#dianping.com
